[xParser] 1.5.0 - Полная поддержка miniShop2 и обновление записей

Наконец-то! Для многих — долгожданный релиз!
Основные нововведения:
- Поддержка товаров miniShop2 (любые свойства/опции)
- Поддержка miniShop2 галереи
- Поддержка ms2Gallery
- Возможность обновления записей
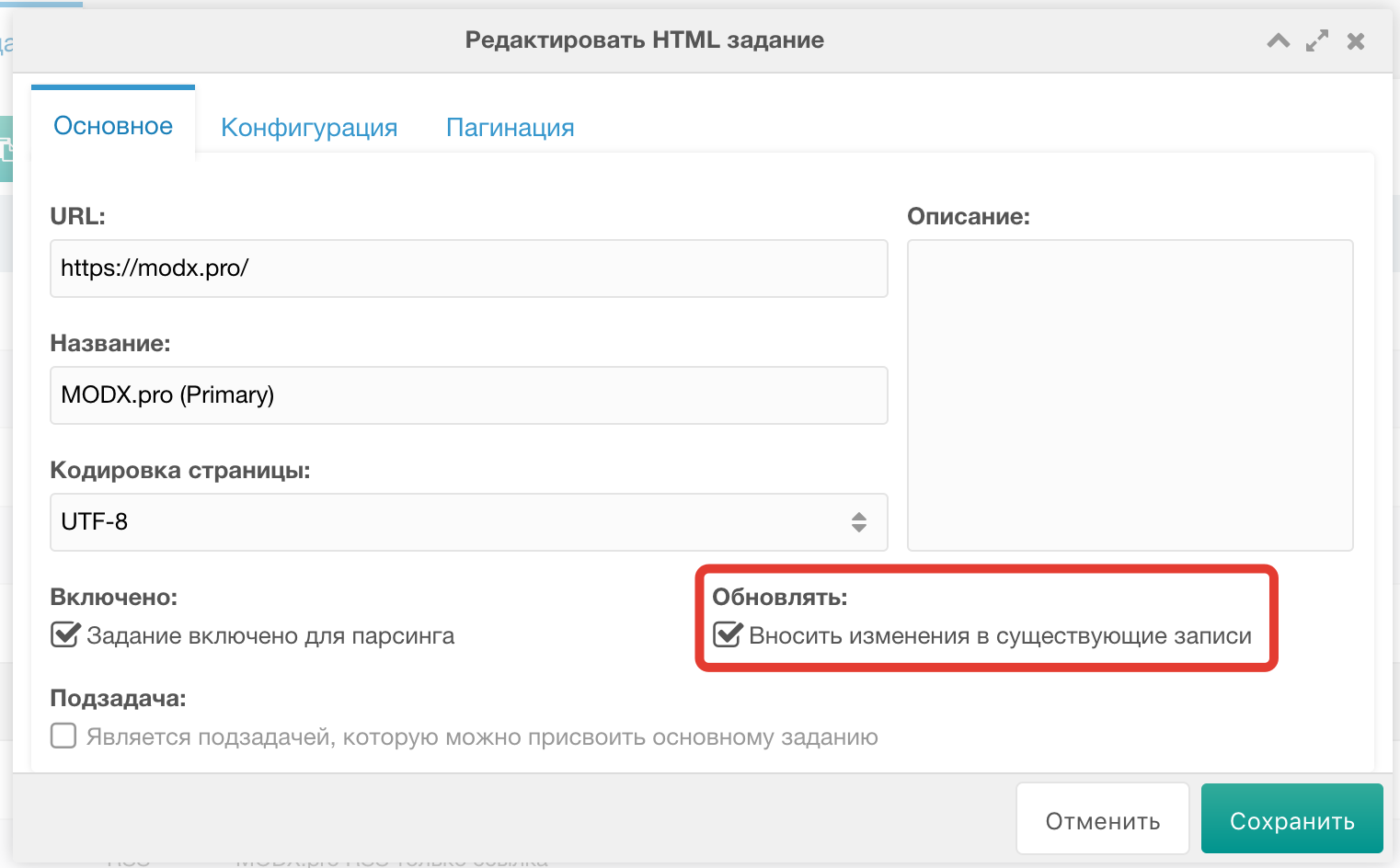
Обновление записей
Для этого при создании/редактировании задания появилась галочка (по-умолчанию, отключено).
ms2Gallery / miniShop2 галерея
Выгружать изображения в галерею, тоже, достаточно просто. Нужно лишь все изображения собрать в JSON массив при помощи Fenom. Вот таким кодом я собрал все изображения, используемые в контенте спарсенной записи, в JSON массив:
@INLINE {($content | preg_get_all : '!https?://[^"]+\.(?:jpe?g|png|gif)!Ui') | toJSON}На выходе, компонент превращает его в обычный массив PHP и по-очереди выгружает в галерею.
Особенности работы с miniShop2 товарами
Есть ряд особенностей, которые следует соблюдать, при создании ms2 товаров при помощи xParser.
1) В конфигурации задания нужно выбрать раздел с типом «Категория товаров».
2) В полях задания нужно создать поле resource | class_key, со значением по-умолчанию: msProduct
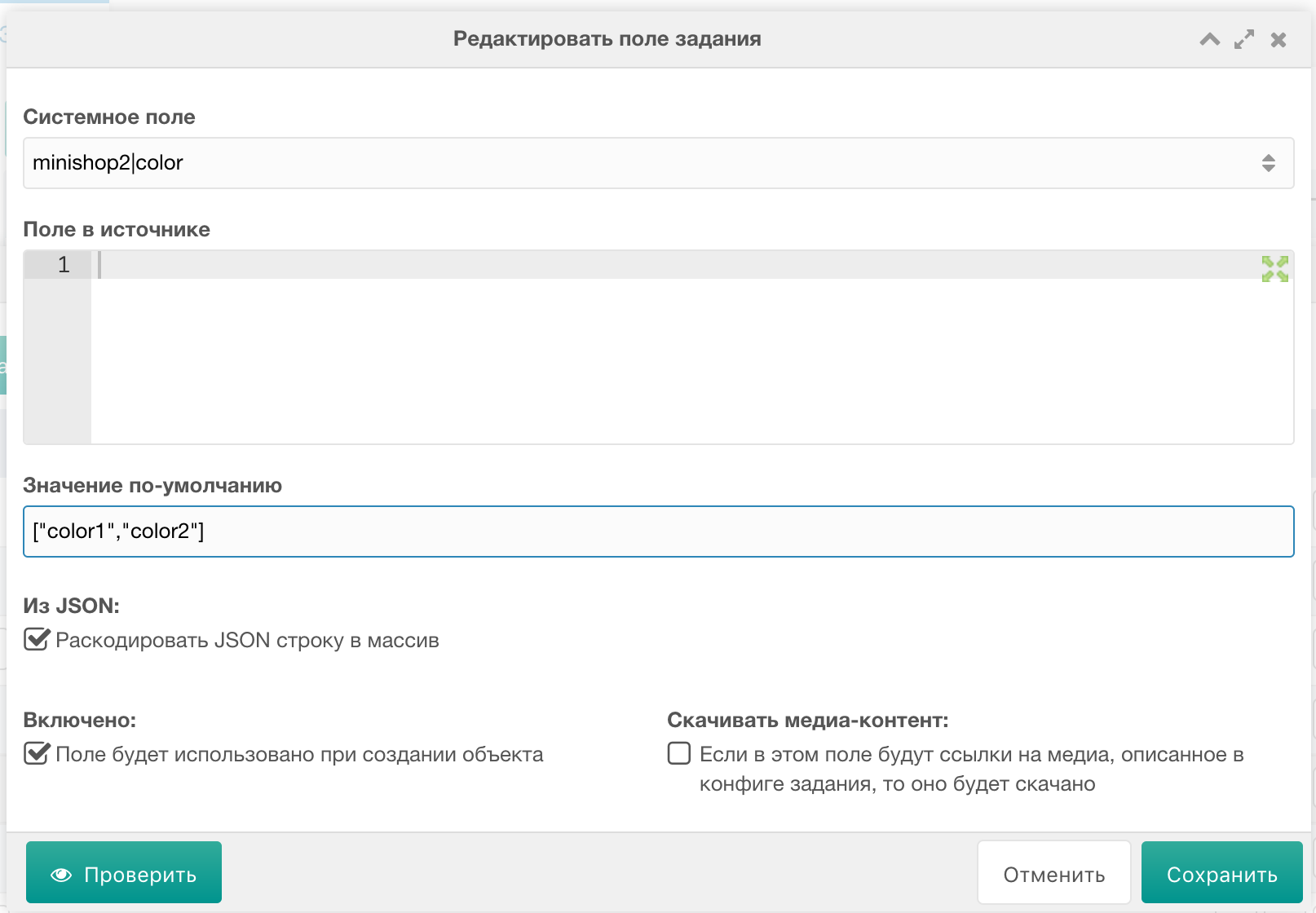
3) Для корректной выгрузки таких полей, как tags, color, size и т.п. при создании полей задания была добавлена настройка «Раскодировать JSON строку в массив». Дело в том, что при создании товаров через процессор, miniShop2 ждет от нас PHP массив для этих полей, поэтому для корректной выгрузки такого типа полей, нужно раскодировать JSON в PHP. К примеру, вот:
msOptionsPrice2
Вот этого компонент пока не поддерживает. Будем внедрять, если найдется спонсор.
P.S.
Компонент скоро будет стоить дороже на 1-2к. Поэтому, если собираетесь покупать — сейчас самое время!
04 ноября 2017, 12:42
Поблагодарить автора
Отправить деньги
Комментарии: 30
Спасибо.
Жаль что нельзя заплатить очень примерными деньгами))
Ну а если без шуток — у нас сейчас работает отдельно человек, который пишет программы парсинга индивидуально для каждого сайта. Потому, что информация на сайтах очень различается по подаче, оформлению, структуре. Где-то характеристики товаров не отображаются, пока не пролистать страницу, а потом грузятся аяксом, где-то изображения товаров это не простые ссылки — это закодированные svg файлы, которые вставляются через JS и защищены от копирования… Все это парсится в XLSX, потом вручную проверяется менеджерами и то — при импорте в minishop все проходит очень не гладко. Если кто-то все это предусмотрел в одном компоненте — я снимаю шляпу.
Жаль что нельзя заплатить очень примерными деньгами))
Ну а если без шуток — у нас сейчас работает отдельно человек, который пишет программы парсинга индивидуально для каждого сайта. Потому, что информация на сайтах очень различается по подаче, оформлению, структуре. Где-то характеристики товаров не отображаются, пока не пролистать страницу, а потом грузятся аяксом, где-то изображения товаров это не простые ссылки — это закодированные svg файлы, которые вставляются через JS и защищены от копирования… Все это парсится в XLSX, потом вручную проверяется менеджерами и то — при импорте в minishop все проходит очень не гладко. Если кто-то все это предусмотрел в одном компоненте — я снимаю шляпу.
Здравствуйте! Может кто встречался с проблемой:
Создал тестовое задание на парсинг 10 ресурсов с картинками в категорию miniShop (как товар с галереей), запустил из cron — в результате, 7 ресурсов идет в категорию miniShop, как и нужно, а 3 ресурса идут как дочерние ресурсы категории miniShop — см. http://clip2net.com/s/3Pz3nrd
Как исправить?
Создал тестовое задание на парсинг 10 ресурсов с картинками в категорию miniShop (как товар с галереей), запустил из cron — в результате, 7 ресурсов идет в категорию miniShop, как и нужно, а 3 ресурса идут как дочерние ресурсы категории miniShop — см. http://clip2net.com/s/3Pz3nrd
Как исправить?
а получится парсить отзывы о товаре с яндекс.маркетаНу если на маркете в отзывах есть структура страницы, которая подгружается в коде страницы, то можно парсить.
И вставлять их в табличку customExtraТут сложнее. Пока не реализован функционал работы со сторонними объектами (не ресурсами). Однако, всегда можно проспонсировать доработку. Если интересно — пишите мне в ТП на modstore.
немного не понял вот эти строки:
На выходе, компонент превращает его в обычный массив PHP и по-очереди выгружает в галерею.Как всетаки заставить xparser загружать изображения в галерею? можно по-шагам. В документации не нашел тоже ничего по этому вопросу.
в общем все понятно, разобрался! полезная ссылка для модификатора preg_get_all
непонятно только что делать вот с этим делом:
непонятно только что делать вот с этим делом:
как бороться с max_execution_time лимитом при парсинге даже около ~50 страниц это занимает больше обычных 60 секунд.
оказалось — проще. просто запустить скрипт cron'а из консоли. тогда все лимиты времени побоку
К сожалению, срок техподдержки истек, поэтому прошу ответить на вопрос — может ли xParser преобразовать относительные URL в абсолютные для их передачи из основного задания в дополнительное?
Пример относительных URL донора на полную версию новости:
Пример относительных URL донора на полную версию новости:
<a href="news-1">Новость 1</a><a href="https://site.com/news-1">Новость 1</a>PHP warning: file_get_contents(news-1): failed to open stream: No such file or directory
Спасибо! Не сочтите за наглость, а как можно получить значения метатегов с помощью RegExp?
Например
Например
<meta property="og:image" content="http://site.com/images/image.jpg"/><meta[^<>]*?og:image['"][^<>]*?content=['"*)*)*)*)*)[(*^<>]*?)['"]https://regex101.com/r/N8oNHE/1
Друзья, кто может помочь — правильно составить XPath выражение для получения метатегов. Гугл подсказывает:
но в XPath мне так и не удалось получить значение поля content в метатеге «description» (пробовал разные вариации).
.//meta[@name='description']/@content.//*[@name='description']/@contentно в XPath мне так и не удалось получить значение поля content в метатеге «description» (пробовал разные вариации).
Спасибо, Павел! Больше всего не хотелось отвлекать именно вас на составление «регулярок».
Но у меня есть вопрос именно по работе xParser — при запуске задания обрабатываются (копируются) ровно 20 записей, хотя в конфигурации указано от 1 до 100 (все 100 записей в коде страницы донора есть, пагинация отсутсвует).
Проблема решается перезарузкой в браузере страницы с запущенным заданием, изменением кофикурации (указываем с 20 до 100) и повторным запуском xParser. При этом он обработает (скопируют) следующие 20 записей (с 20 по 40). В логе ошибок нет, как будто парсер просто «зависает».
Перечитал документацию, комментарии — нигде об этой особенности не упоминается. Может отработка по 20 заданий специально предусмотрена для работы через крон?
Но у меня есть вопрос именно по работе xParser — при запуске задания обрабатываются (копируются) ровно 20 записей, хотя в конфигурации указано от 1 до 100 (все 100 записей в коде страницы донора есть, пагинация отсутсвует).
Проблема решается перезарузкой в браузере страницы с запущенным заданием, изменением кофикурации (указываем с 20 до 100) и повторным запуском xParser. При этом он обработает (скопируют) следующие 20 записей (с 20 по 40). В логе ошибок нет, как будто парсер просто «зависает».
Перечитал документацию, комментарии — нигде об этой особенности не упоминается. Может отработка по 20 заданий специально предусмотрена для работы через крон?
Авторизуйтесь или зарегистрируйтесь, чтобы оставлять комментарии.
Здесь упомянуты:
| Компонент | Текущая версия | Закачки |
| xParser | 1.12.5-beta от 12.03.2026 | 771 |
| miniShop2 | 4.4.2-pl от 06.10.2025 | 27 212 |
| ms2Gallery | 2.0.12-pl от 25.09.2020 | 4 669 |
| msOptionsPrice2 | 2.5.22-beta от 29.11.2019 | 5 766 |
| customExtra | 2.0.4-beta от 09.07.2019 | 146 |
| RSS | 1.5.0-pl от 03.12.2019 | 4 |
13 июня 2026, 08:29
С другого старого сайта, вот держи
11 июня 2026, 21:58
Позже, может размещу и на docs.modx.pro, пока времени нет
11 июня 2026, 15:40
Добрый день! А можно как-то в чанк сниппета msOptionsPrice.option вывести цену? prnt.sc/cfX_WTwINTVL
Сам чанк {foreach $options as $name => $...
11 июня 2026, 15:36
Для последних версий (msOptionsPrice2 — 2.5.22-beta и msDiscount — 1.3.13-pl) не работает
10 июня 2026, 08:31
rumaxbot.ru/email/verification-notification
выдает ошибку:
# Symfony\Component\HttpKernel\Exception\MethodNotAllowedHttpException - Method Not ...
05 июня 2026, 09:38
Я не знаком с cityField. Смотрите, чем отличаются формы и запросы на сервер. Если разные контексты — то проверьте, как настроены источники файлов.
04 июня 2026, 20:21
У кого нет юрлица, то можно использовать бота-прослойку: modx.pro/development/25531