[xParser] Парсер RSS лент
Парсер контента RSS лент, с возможностью скачивания медиа-контента на сайт.

При добавлении полей ленты, которые надо парсить, вместо названия поля (title или enclosure[url]) можно указать @INLINE чанк, который будет обработан Fenom. Благодаря этому, в этих полях можно выстраивать совершенно любую логику, вплоть до создания новых разделов «на ходу».
Стояла задача, как можно больше упростить взаимодействие с компонентом, поэтому жду мнений, насколько компонент прост в управлении.
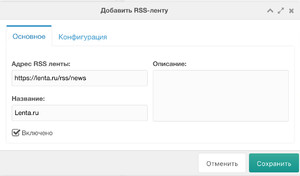
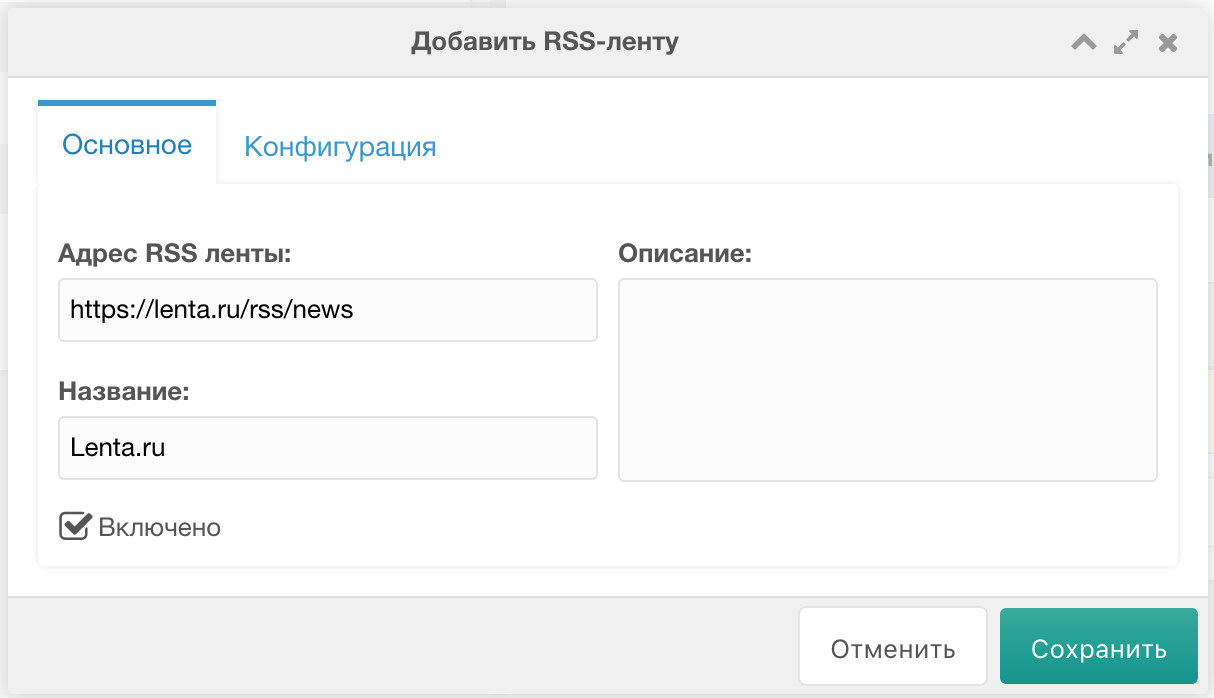
На вкладке Основное заполняем примерно так:
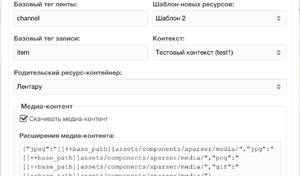
Переключаемся на вкладку Конфигурация, где можно указать:
Расширения медиа-контента и папки для сохранения каждого из расширений указываются в JSON.
Жмём Сохранить — задание добавлено!
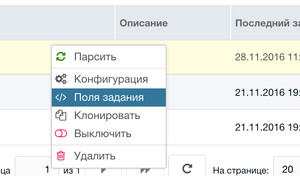
Откроется список полей задания, который пока пуст.
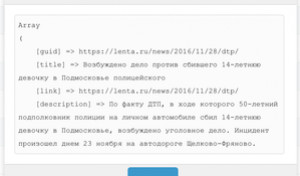
Помимо добавления полей задания мы можем просмотреть Массив значений ленты — это распечатанный массив с данным из первой записи ленты:
Запоминаем названия полей, которые нам надо парсить на сайт и кликаем Добавить поле. Откроется окошко с возможностью указать:
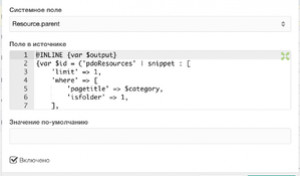
Помимо основых полей с данными, которые необходимо выгрузить на сайт, нам надо ещё добавить поле, по которому пакет будет понимать, что данная запись уже есть на сайте. Для этого добавляем новое поле, значение Системное поле оставляем пустым, а в Поле в источнике пишем, например, «guid» (потому что он менее всего подвержен изменениям). Должно быть как-то так:
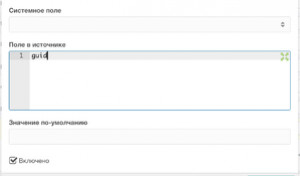
Сохраняем. В списке полей на этом поле ставим указатель Уникальное поле (кнопка со звездой слева):
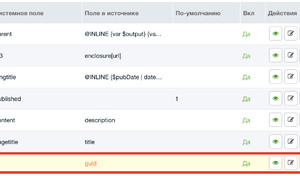
Всё готово к парсингу, как к единоразовому, так и к ежеминутному (у компонента есть скрипт для запуска заданий из крона).
Спасибо Владимиру за спонсорскую поддержку!
P.S. Владимиру этим компонентом, даже, как-то удавалось запускать импорт из WordPress в MODX. Надеюсь, он нам расскажет, как это сделать.
При добавлении полей ленты, которые надо парсить, вместо названия поля (title или enclosure[url]) можно указать @INLINE чанк, который будет обработан Fenom. Благодаря этому, в этих полях можно выстраивать совершенно любую логику, вплоть до создания новых разделов «на ходу».
Подробнее о работе
Стояла задача, как можно больше упростить взаимодействие с компонентом, поэтому жду мнений, насколько компонент прост в управлении.
Добавляем задание
Заходим на страницу компонента, жмём Добавить задание => Добавить RSS-ленту.На вкладке Основное заполняем примерно так:
Переключаемся на вкладку Конфигурация, где можно указать:
- Шаблон для создаваемых ресурсов,
- Контекст,
- Родительский контейнер в пределах выбранного контекста,
- Сконфигурировать скачивание медиа-контента,
- При необходимости поменять базовый тег ленты и базовый тег записи.
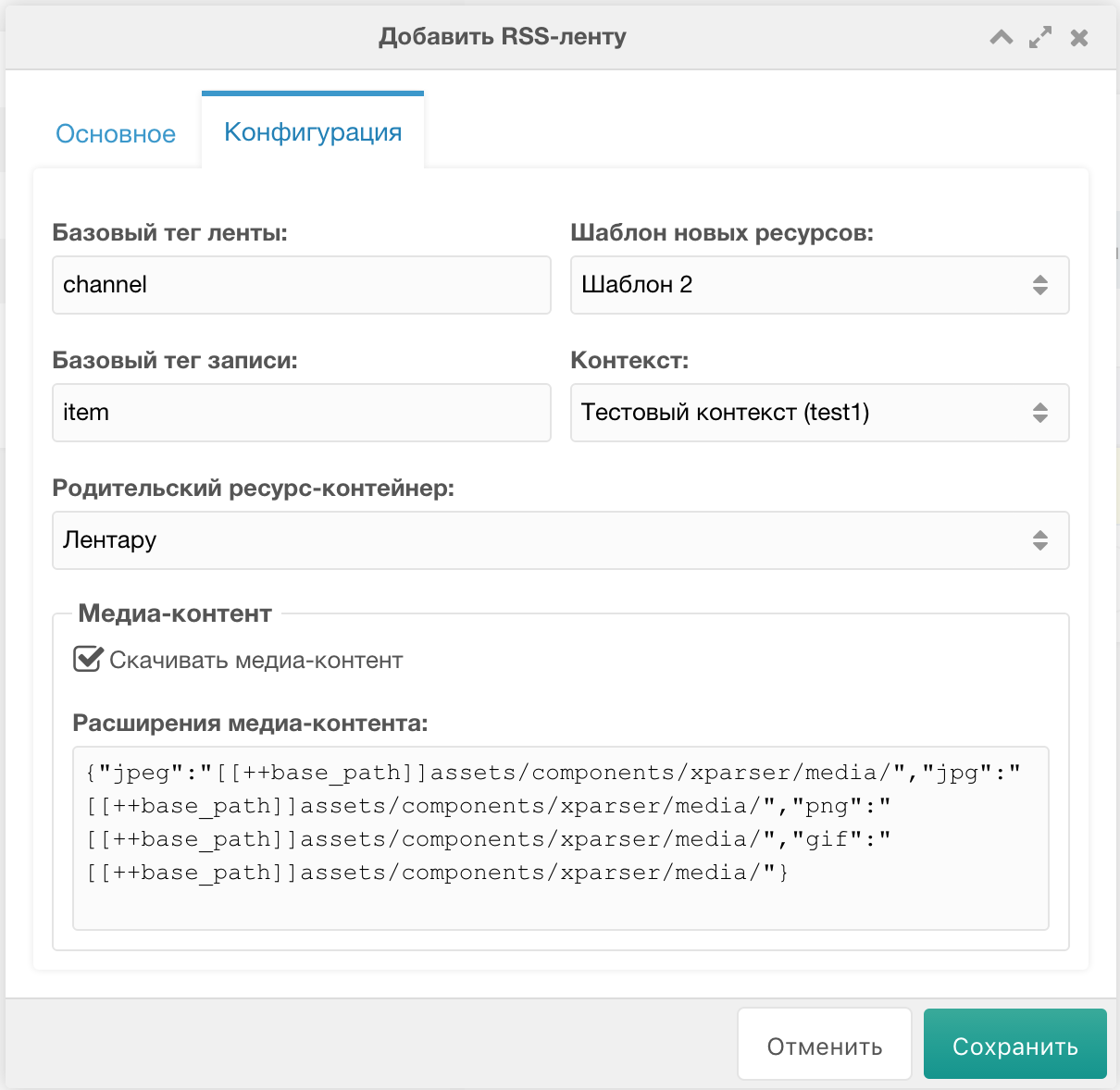
Расширения медиа-контента и папки для сохранения каждого из расширений указываются в JSON.
Жмём Сохранить — задание добавлено!
Добавляем поля для парсинга
На только что добавленном задании нажимаем правой кнопкой и выбираем Поля задания:
Откроется список полей задания, который пока пуст.
Помимо добавления полей задания мы можем просмотреть Массив значений ленты — это распечатанный массив с данным из первой записи ленты:
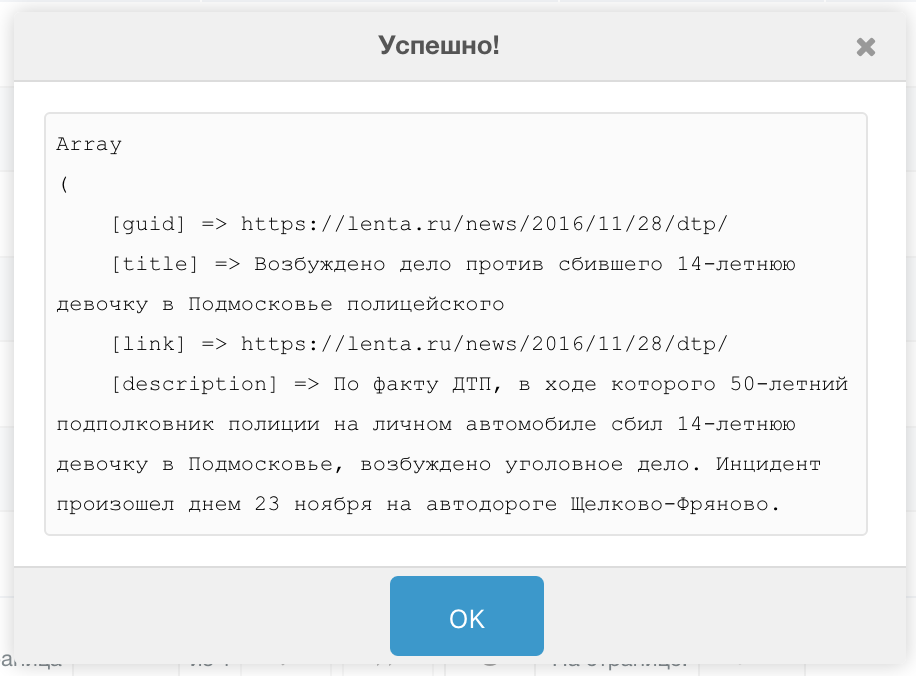
Запоминаем названия полей, которые нам надо парсить на сайт и кликаем Добавить поле. Откроется окошко с возможностью указать:
- Системное поле. Выпадающий список системных полей ресурса и ТВ-полей.
- Поле в источнике. Текстовое поле, в которое нужно ввести наименование тега в RSS-ленте.
Можно указать @INLINE чанк, который будет обработан Fenom из pdoTools. В чанке содержатся плейсхолдеры всех возможных полей из RSS-ленты, которые имеются в записи между тегами item, а также массив с настройками задания $_task.
За счёт внедрения в данное поле Fenom, можно будет, получая значение из тега category (как например в RSS Lenta.ru) делать выборку по базе ресурсов, в поисках ID аналогичной категории на нашем сайте, а если не найдено — добавлять.
Тег enclosure и ему подобные, указываются либо через чанк: «@INLINE {$enclosure['url']}», либо в виде CSS селектора: «enclosure[url]».
Если не указано или значение по данному полю в ленте пустое, то в качестве значения для Системное поле будет взято значение из следующего поля — Значение по-умолчанию.
- Значение по-умолчанию. В данном поле можно указать значение, которое будет записано в Системное поле. Например, если мы в Системное поле выбрали class_key, то, чтобы создавались Тикеты, мы в поле Значение по-умолчанию пишем «Ticket», а Поле в источнике оставляем пустым.
Такую же «магию» можно сделать и с полем published, указав в значении по-умолчанию цифру «1». Тогда ресурс на сайт будет добавляться сразу опубликованным.
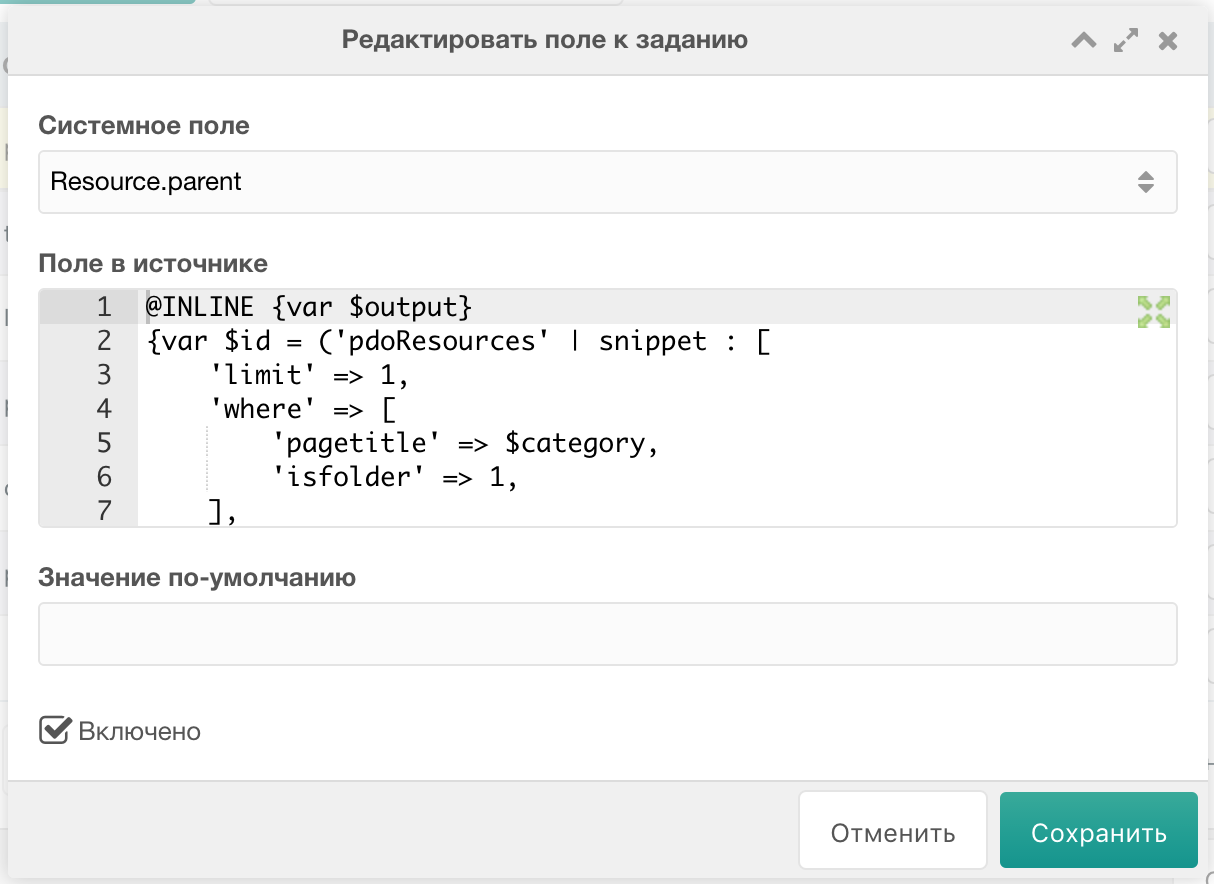
Помимо основых полей с данными, которые необходимо выгрузить на сайт, нам надо ещё добавить поле, по которому пакет будет понимать, что данная запись уже есть на сайте. Для этого добавляем новое поле, значение Системное поле оставляем пустым, а в Поле в источнике пишем, например, «guid» (потому что он менее всего подвержен изменениям). Должно быть как-то так:
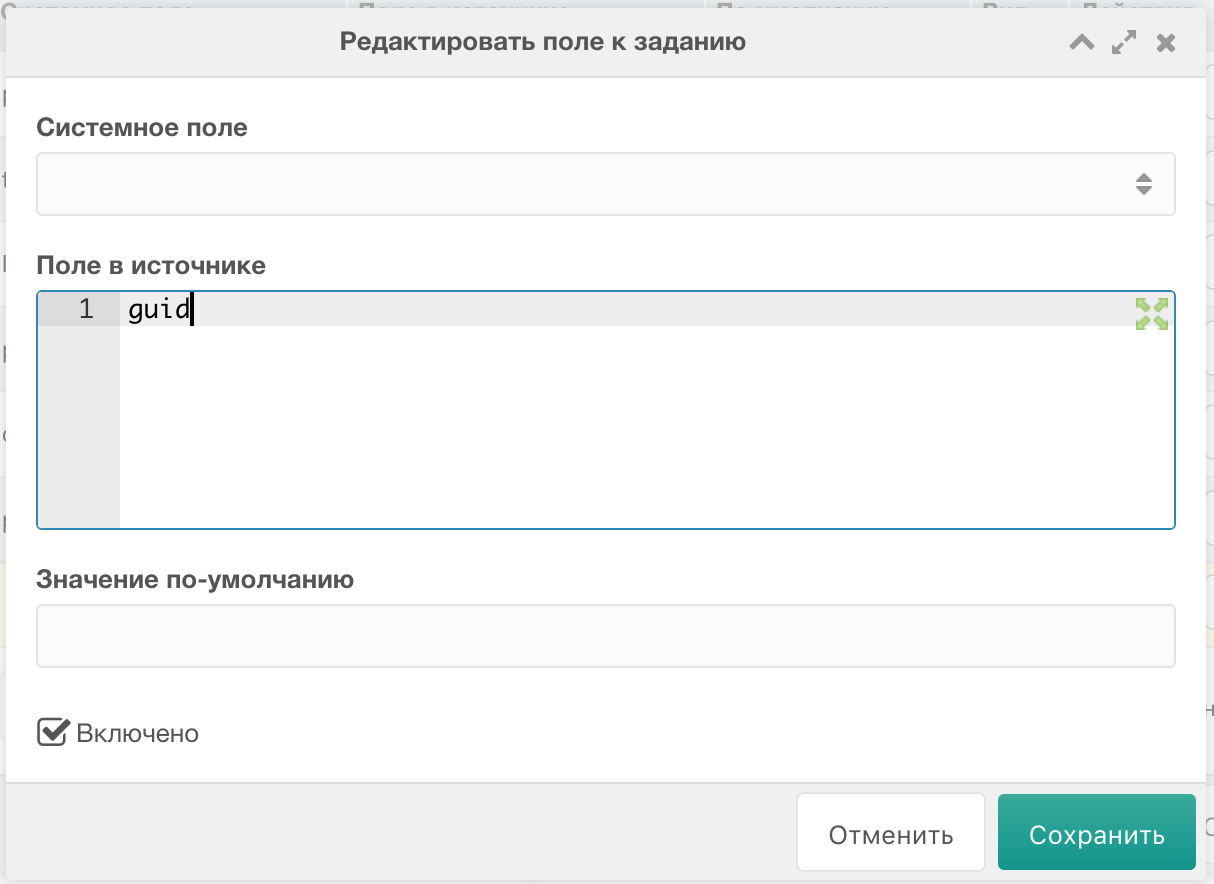
Сохраняем. В списке полей на этом поле ставим указатель Уникальное поле (кнопка со звездой слева):
Всё готово к парсингу, как к единоразовому, так и к ежеминутному (у компонента есть скрипт для запуска заданий из крона).
Спасибо Владимиру за спонсорскую поддержку!
P.S. Владимиру этим компонентом, даже, как-то удавалось запускать импорт из WordPress в MODX. Надеюсь, он нам расскажет, как это сделать.
А теперь о развитии
1990 рублей — это не окончательная стоимость компонента, по мере развития стоимость будет только повышаться.Готово!Компонент будет расширяться до парсера HTML контента.Готово!Есть идея совмещения типов парсера (RSS лент и HTML контента). К примеру, в RSS лентах всегда присутствует ссылка на полную статью. В планах сделать так, чтобы воспользовавшись этим полем со ссылкой, передавать задание парсинга из RSS ленты в соседнее задание, которое настроено именно на этот HTML контент. Естественно, данная идея будет реализована только после того, как реализуется сам тип заданий «HTML контент».Готово!- Будет внедрена поддержка ms2Gallery, UserFiles2, modClassVar. Что ещё?
- Если есть интересные идеи развития компонента — высказывайтесь.
Купить дополнение в modstore.pro
Комментарии: 94
Авторизуйтесь или зарегистрируйтесь, чтобы оставлять комментарии.
Например, мне нужен документ на сайте с заголовком (ключевой фразой) «Парсеры RSS лент», а xParser его автоматически создаст из результатов выдачи посковиков.
В первом пункте можно в ручную задать тематику сайтов для поиска «Политика». А еще лучше, чтобы парсер брал тематику из названия рубрики, в которой будет публиковать подборку.
Надоело платить тупым копирайтерами за тексты, которые приходится почти полностью переписывать. Лучше я один раз заплачу тебе и буду редактировать тексты от парсера.
P.S. — не тупые копирайтеры мне пока не по карману
По поводу пожелания, то вряд ли такое будет реализовано, по крайней мере в ближайшем будущем. Это всё же парсер, а не ИИ какой-то. :)
Кто украл то?) На днях, как будто, было больше.
такой компонент очевидный вклад в популяризацию MODX)
При установке выдавало ошибку
Подскажите как это можно исправить?
АнтонЕсть ли в нем возможность замены слов?
По замене слов: опишите подробнее, возможно, что получится решить исключительно средствами Fenom.
Короче, придется написать об опыте использования.
На одном сайте xParser — это агрегатор новостей, на другом обмен партнерскими материалами. Использование этого инструмента — вопрос предприимчивости, а может он уже многое.
P.S. С ужасом понял, что в docs.modx.pro про работу с ms2 ни слова… Исправим!
Если по действиям, то примерно так:
1) нахожу какую то интересную статью (на рус или англ м.б.)
2) копирую ссылку
3) создаю тикет ( у меня сайт на тикетах и феном)
4) тикету даю на вход эту ссылку
5) тикет берт Оглавнение, Описание и сам контент (может даже не весь)
Интересует парсер товаров для modx на подобие модуля «Автоматическая обработка прайслистов» для opencart. Принцип его работы заключается в следующем.
Есть прайс, к примеру, на 500 товаров в excel. Я к каждому товару нахожу ссылку откуда парсить данные (т.е. с другого сайта, который мне понравится, этот же товар). Как правило после обработки всего прайслиста на выходе получается определенное количество сайтов, с которых будем парсить данные. К примеру, 7 штук.
Далее в модуле создаются шаблоны на парсинг под каждый из найденных сайтов. Там мы вводим разметку для необходимых типов данных с этих самых сайтов, т.е. как начинается необходимое поле и как заканчивается. Под каждый найденный сайт свой шаблон. К примеру, заголовок: в поле «Начало» вводим , а в поле «Конец» — . Все что между данными тегами, заносится в заголовок. И так далее с остальными данными, будь то описание, атрибуты (характеристики), изображения, цена и т.п.
Таким образом можно достаточно быстро наполнить магазин товарами со всеми необходимыми данными.
Ссылка на видео с обзором от автора модуля: www.youtube.com/watch?v=aCaoSaS3JC8&list=PLkDV_NaX_cBAerpeAke8cdw1Weom6jov_&index=10
Вопрос. Может ли данный парсер делать то же самое?
Спасибо!
Есть у меня к примеру xml
вот кусок
вот какие нужно поставить значение к примеру для тега vendor, т.е. это категория товара (minishop2|categories) на сколько я понял.
Но как его записать в «поле источника» что бы оно тянуло верно в minishop2|categories?
file.modx.pro/files/e/4/9/e4945ce95acb1f355845fde2ab8eed8a.png