[xParser] 1.5.0 - Полная поддержка miniShop2 и обновление записей

Наконец-то! Для многих — долгожданный релиз!
Основные нововведения:
- Поддержка товаров miniShop2 (любые свойства/опции)
- Поддержка miniShop2 галереи
- Поддержка ms2Gallery
- Возможность обновления записей
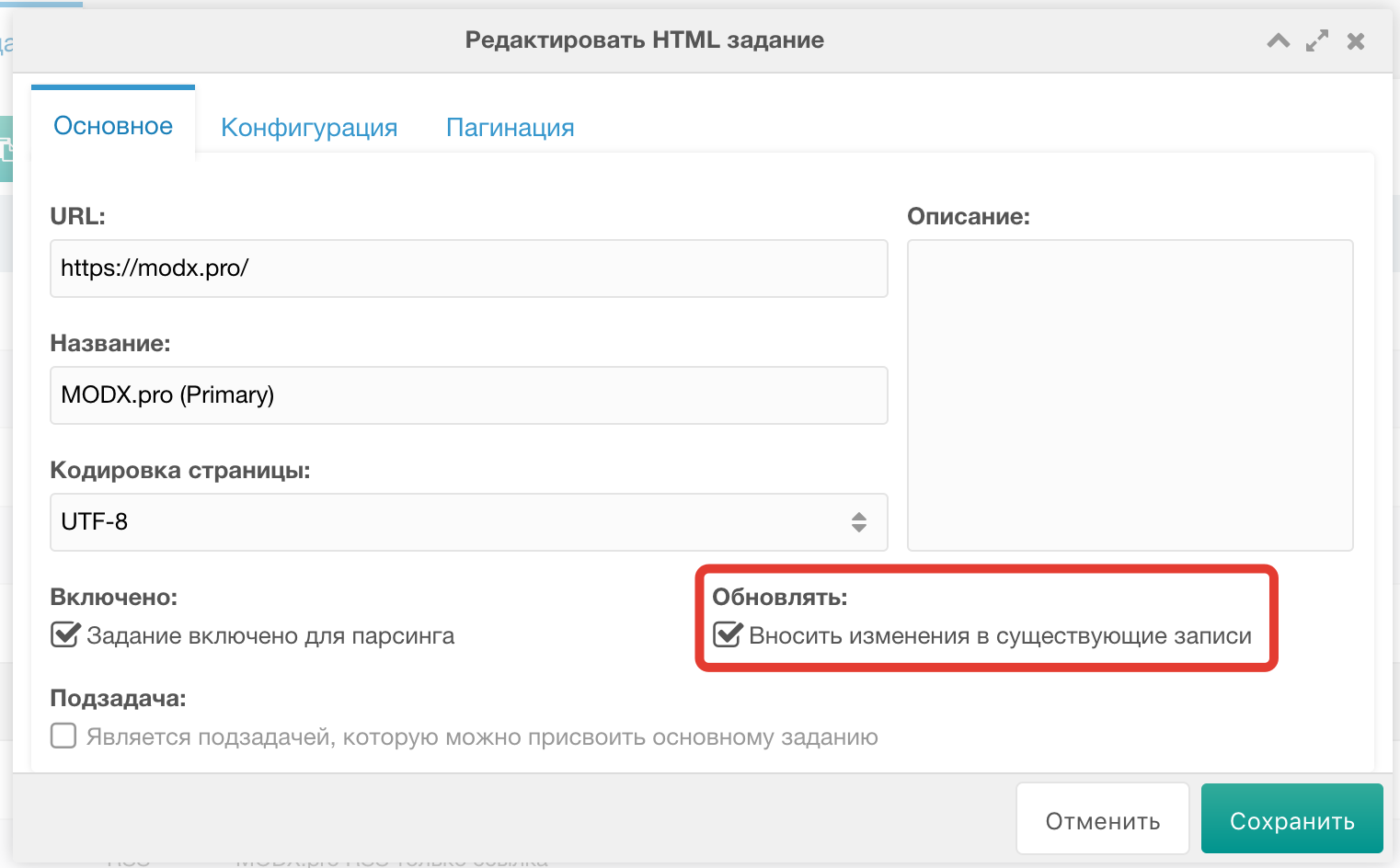
Обновление записей
Для этого при создании/редактировании задания появилась галочка (по-умолчанию, отключено).
ms2Gallery / miniShop2 галерея
Выгружать изображения в галерею, тоже, достаточно просто. Нужно лишь все изображения собрать в JSON массив при помощи Fenom. Вот таким кодом я собрал все изображения, используемые в контенте спарсенной записи, в JSON массив:
@INLINE {($content | preg_get_all : '!https?://[^"]+\.(?:jpe?g|png|gif)!Ui') | toJSON}На выходе, компонент превращает его в обычный массив PHP и по-очереди выгружает в галерею.
Особенности работы с miniShop2 товарами
Есть ряд особенностей, которые следует соблюдать, при создании ms2 товаров при помощи xParser.
1) В конфигурации задания нужно выбрать раздел с типом «Категория товаров».
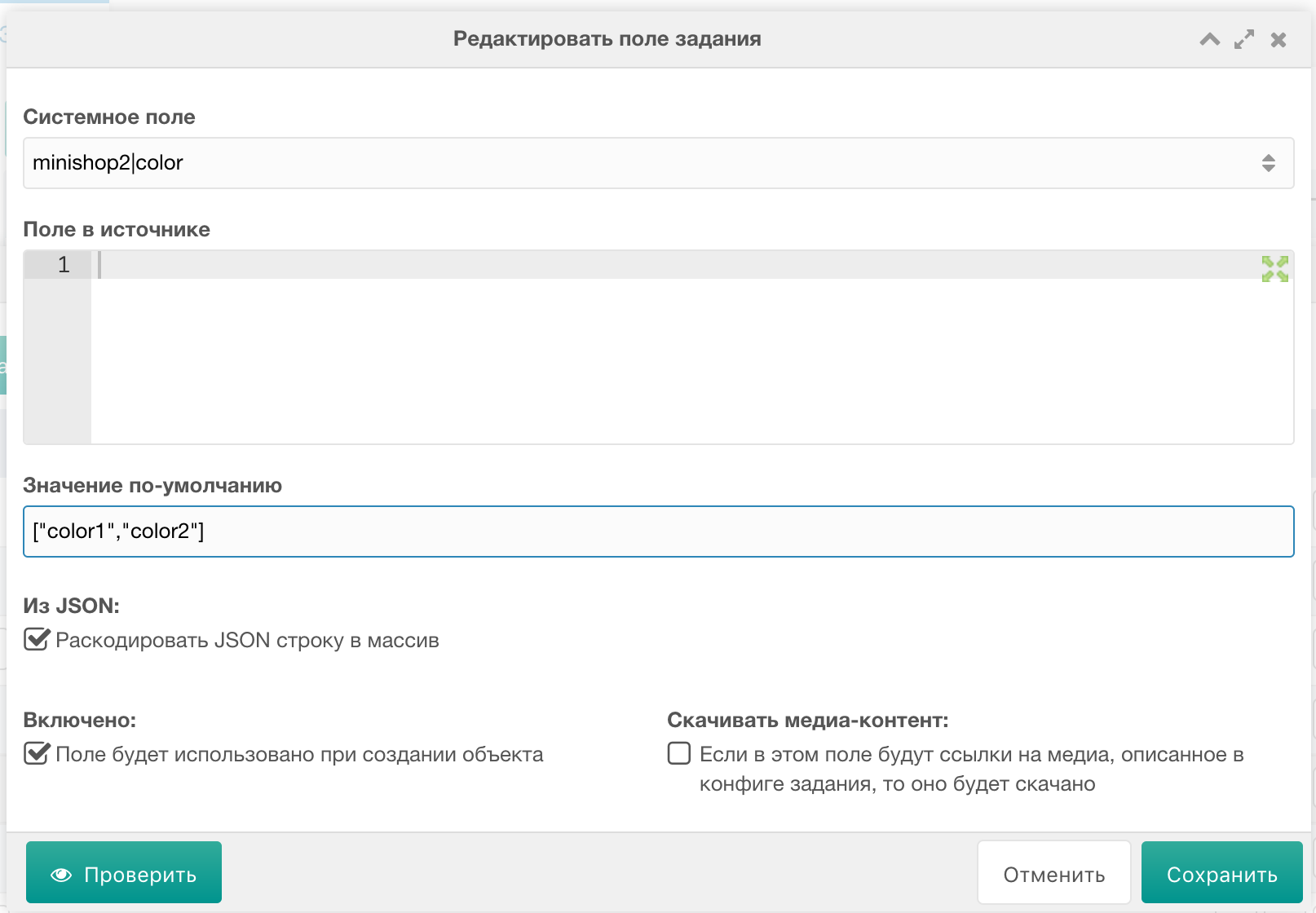
2) В полях задания нужно создать поле resource | class_key, со значением по-умолчанию: msProduct
3) Для корректной выгрузки таких полей, как tags, color, size и т.п. при создании полей задания была добавлена настройка «Раскодировать JSON строку в массив». Дело в том, что при создании товаров через процессор, miniShop2 ждет от нас PHP массив для этих полей, поэтому для корректной выгрузки такого типа полей, нужно раскодировать JSON в PHP. К примеру, вот:
msOptionsPrice2
Вот этого компонент пока не поддерживает. Будем внедрять, если найдется спонсор.
P.S.
Компонент скоро будет стоить дороже на 1-2к. Поэтому, если собираетесь покупать — сейчас самое время!
Комментарии: 30
Авторизуйтесь или зарегистрируйтесь, чтобы оставлять комментарии.
Жаль что нельзя заплатить очень примерными деньгами))
Ну а если без шуток — у нас сейчас работает отдельно человек, который пишет программы парсинга индивидуально для каждого сайта. Потому, что информация на сайтах очень различается по подаче, оформлению, структуре. Где-то характеристики товаров не отображаются, пока не пролистать страницу, а потом грузятся аяксом, где-то изображения товаров это не простые ссылки — это закодированные svg файлы, которые вставляются через JS и защищены от копирования… Все это парсится в XLSX, потом вручную проверяется менеджерами и то — при импорте в minishop все проходит очень не гладко. Если кто-то все это предусмотрел в одном компоненте — я снимаю шляпу.
Создал тестовое задание на парсинг 10 ресурсов с картинками в категорию miniShop (как товар с галереей), запустил из cron — в результате, 7 ресурсов идет в категорию miniShop, как и нужно, а 3 ресурса идут как дочерние ресурсы категории miniShop — см. http://clip2net.com/s/3Pz3nrd
Как исправить?
Тут сложнее. Пока не реализован функционал работы со сторонними объектами (не ресурсами). Однако, всегда можно проспонсировать доработку. Если интересно — пишите мне в ТП на modstore.
Как всетаки заставить xparser загружать изображения в галерею? можно по-шагам. В документации не нашел тоже ничего по этому вопросу.
непонятно только что делать вот с этим делом:
либо в php.ini либо через .htaccess если у вас апачи
Есть ли возможность с помощью данного компонента парсить данные в свою таблицу, чтобы не перегружать дерево ресурсов?
Пример относительных URL донора на полную версию новости:
вместо абсолютных:
При попыке выполнить задание, xParser вполне обосновано пишет в лог ошибки-
Например
Пишем «регулярку»
Проверяем на валидность, все работает
Вставляю «регулярку» в xParser — пусто.
но в XPath мне так и не удалось получить значение поля content в метатеге «description» (пробовал разные вариации).
Но у меня есть вопрос именно по работе xParser — при запуске задания обрабатываются (копируются) ровно 20 записей, хотя в конфигурации указано от 1 до 100 (все 100 записей в коде страницы донора есть, пагинация отсутсвует).
Проблема решается перезарузкой в браузере страницы с запущенным заданием, изменением кофикурации (указываем с 20 до 100) и повторным запуском xParser. При этом он обработает (скопируют) следующие 20 записей (с 20 по 40). В логе ошибок нет, как будто парсер просто «зависает».
Перечитал документацию, комментарии — нигде об этой особенности не упоминается. Может отработка по 20 заданий специально предусмотрена для работы через крон?
Это если я запускал парсер через консоль.
Пытаюсь получить ссылки, не получается