[xParser] 1.2.0 - Парсер HTML контента + совмещение заданий
Парсер HTML контента востребованная штука, поэтому естественным шагом было его внедрение в xParser.

А с версии 1.2.0 компонент позволяет совмещать задания. Например, вам нужно распарсить RSS ленту и каждую запись выпилить с сайта полностью. Для этого:
Так как в RSS ленте у нас по-умолчанию присутствует некий массив полей, которые можно распределить по полям MODX, то в HTML дела обстоят несколько сложнее: нам нужно самим создать эти поля, указав селектор до каждого из них.
Давайте на примере MODX.pro рассмотрим, как это делается:
Покажу пример, в котором происходит запуск одного задания из другого. Для этого нам надо будет создать 2 задания:
Жмём Добавить => Добавить HTML задание.
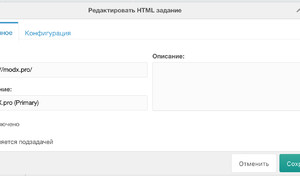
На вкладке Основное заполняем примерно так:
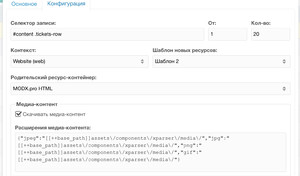
Переключаемся на вкладку Конфигурация, где указываем:
Жмём Сохранить — задание добавлено!
Жмём Добавить => Добавить HTML задание.
На вкладке Основное заполняем примерно так:
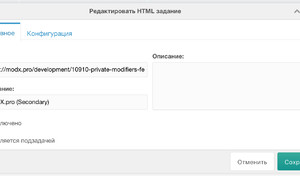
Важно указать:
Так как задания у нас типа HTML, то придётся вручную создавать данные источника, которые будем парсить. Потребуется сделать это также, для двух заданий. Жмём на задании правой мышью => Источник.
Здесь у нас есть возможность указать CSS-подобный или XPath синтаксис. Для разных полей часто требуется и тот, и другой.
Внимание: XPath синтаксис имеет неприятный баг: не понимает названия тегов, поэтому приходится указывать тег, как *
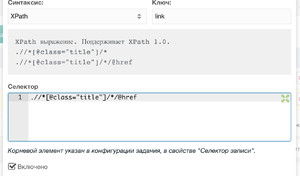
Заполняем примерно так:
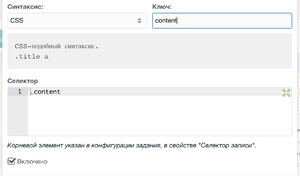
Там же можно проверить, насколько корректно парсер получает указанные нами значения. Для этого требуется нажать на кнопку с глазом:

Pagetitle:
Синтаксис: CSS
Ключ: pagetitle
Селектор: h3.page-title
Content:
Синтаксис: CSS
Ключ: content
Селектор: .page-content
По большому счёту тут всё очень похоже на настройку RSS задания, т.к. у нас уже есть данные из источника, которые можно просмотреть в виде распечатанного массива, кликнув по кнопке Массив сырых значений. Сейчас нам надо, опираясь на эти ключи и значения источника, правильно добавить поля для парсинга. Жмём на задании правой мышью => Поля.
Описывать подробно возможности пакета на данном этапе не буду, кому интересно, может почитать это в описании настройки RSS заданий.
Link:
Системное поле: пусто
Поле в источнике: link
Значение по-умолчанию: пусто
Introtext: (запишем сюда изображение)
Системное поле: Resource.introtext
Поле в источнике:
Теперь в таблице добавленных полей задания у поля link кликаем на звезду (поле должно стать оранжевым) и на соседнюю кнопку. Откроется окошко добавления связанного задания. Там есть сноска, продублирую:
В поле Принимающее задание выбираем MODX.pro (Secondary). Таким образом, текущее задание (Primary) передаст УРЛ из поля link в задание (Secondary). Жмём Сохранить. Поле link в таблице подсветится синим цветом:
Pagetitle:
Системное поле: Resource.pagetitle
Поле в источнике:
Content:
Системное поле: Resource.content
Поле в источнике: content
Значение по-умолчанию: пусто
Published:
Системное поле: Resource.published
Поле в источнике: пусто
Значение по-умолчанию: 1
Компонент успешно развивается и будет развиваться, обрастая всё новыми плюшками. Планов много, гораздо больше, чем времени на их реализацию. Тем не менее, предложения об улучшениях принимаются с радостью.
P.S.: Следующим шагом будет внедрение возможности путешествия по страницам.
P.P.S.: Компонент успешно вырос из логотипа, надеюсь modstore заметит это. :)
А с версии 1.2.0 компонент позволяет совмещать задания. Например, вам нужно распарсить RSS ленту и каждую запись выпилить с сайта полностью. Для этого:
- Создаётся пара заданий (первое — RSS, второе — HTML),
- Настраивается,
- Запускается.
Подробнее об HTML парсере
Так как в RSS ленте у нас по-умолчанию присутствует некий массив полей, которые можно распределить по полям MODX, то в HTML дела обстоят несколько сложнее: нам нужно самим создать эти поля, указав селектор до каждого из них.
Давайте на примере MODX.pro рассмотрим, как это делается:
Добавляем задания
Покажу пример, в котором происходит запуск одного задания из другого. Для этого нам надо будет создать 2 задания:
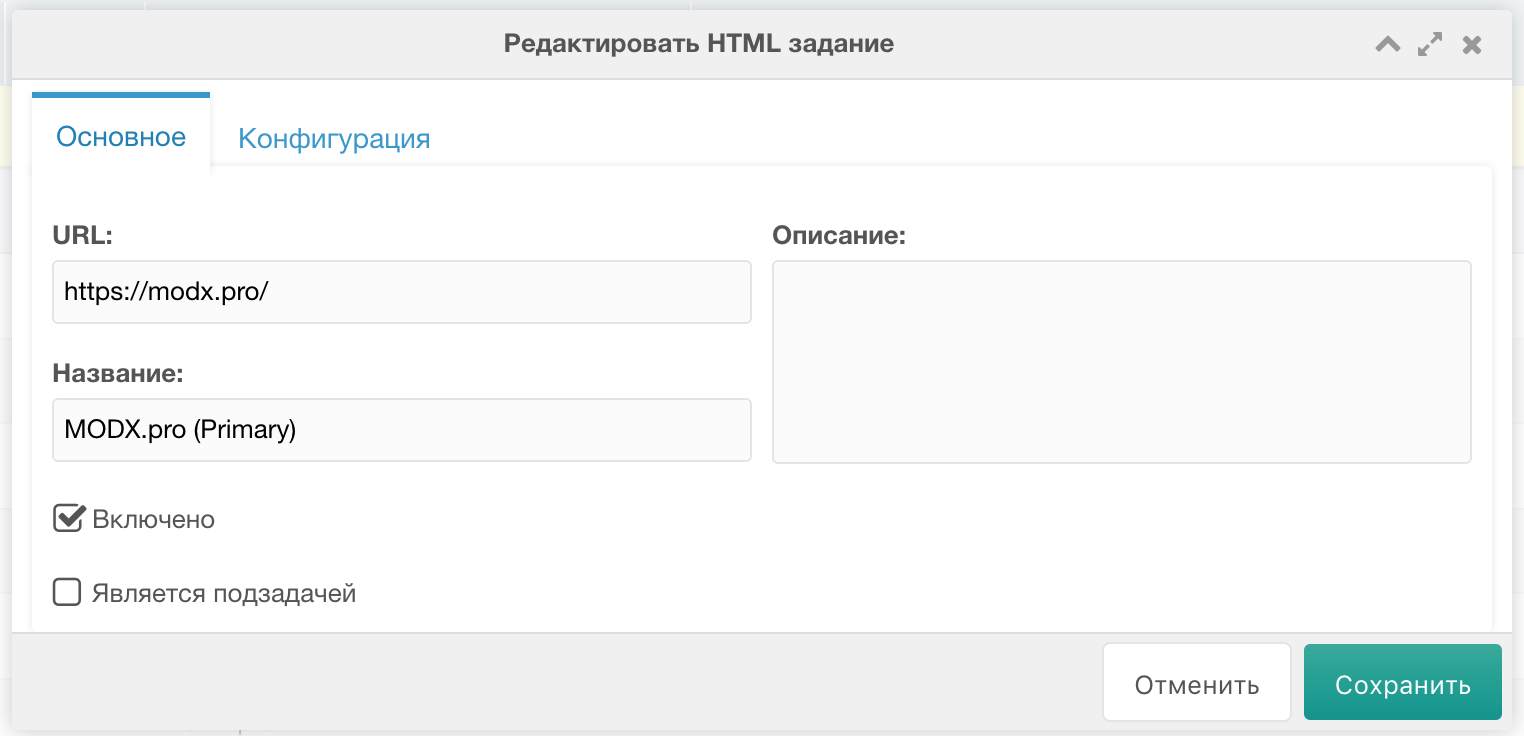
Добавляем primary задание
Primary заданием я называю список новостей, которые нам необходимо распарсить.Жмём Добавить => Добавить HTML задание.
На вкладке Основное заполняем примерно так:
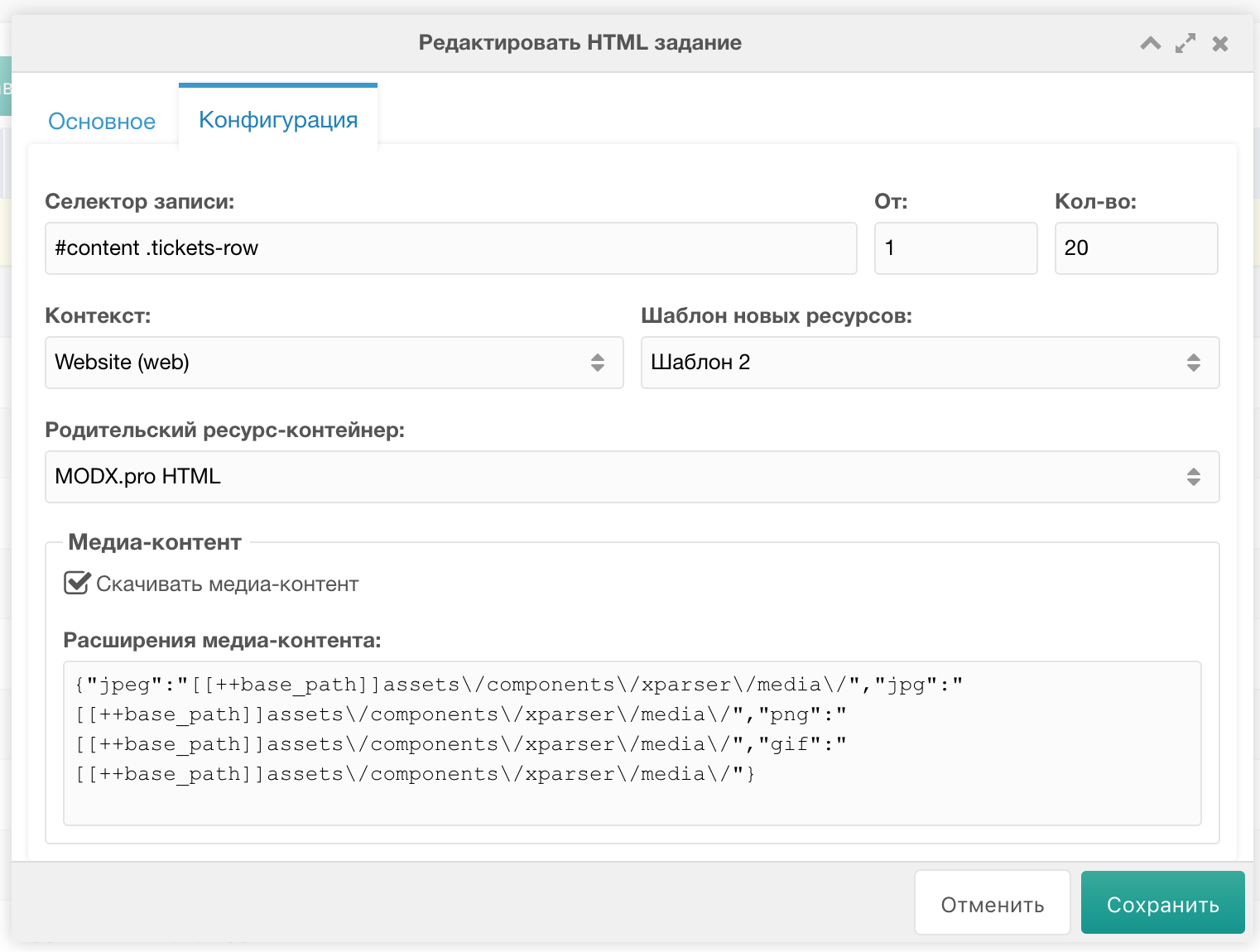
Переключаемся на вкладку Конфигурация, где указываем:
- Селектор записи (пока только CSS-подобный синтаксис),
- С какой по счёту записи стартовать,
- Сколько записей парсить,
- Шаблон для создаваемых ресурсов,
- Контекст,
- Родительский контейнер в пределах выбранного контекста,
- Скачивать ли медиа-контент.
Жмём Сохранить — задание добавлено!
Добавляем secondary задание
Secondary заданием я называю задание с настройкой парсинга для полной статьи. Его мы будем указывать в качестве наследника для первого задания.Жмём Добавить => Добавить HTML задание.
На вкладке Основное заполняем примерно так:
Важно указать:
- URL — ссылку на какую-нибудь статью с modx.pro (потребуется для настройки полей источника),
- Поставить галочку Является подзадачей.
- Селектор записи: #content
Настройка источника
Так как задания у нас типа HTML, то придётся вручную создавать данные источника, которые будем парсить. Потребуется сделать это также, для двух заданий. Жмём на задании правой мышью => Источник.
Настройка источника для primary задания
Здесь достаточно добавить всего 1 поле — ссылку на полную версию статьи. Однако, я предлагаю добавить ещё и поле content, в котором будет храниться вступительная часть статьи. В этом вступительном тексте также указывается основное изображение статьи, вот его то мы и будем выдирать с помощью регулярки. Происходить это будет на шаге Настройки полей primary задания. Жмём Добавить.Здесь у нас есть возможность указать CSS-подобный или XPath синтаксис. Для разных полей часто требуется и тот, и другой.
Внимание: XPath синтаксис имеет неприятный баг: не понимает названия тегов, поэтому приходится указывать тег, как *
Заполняем примерно так:
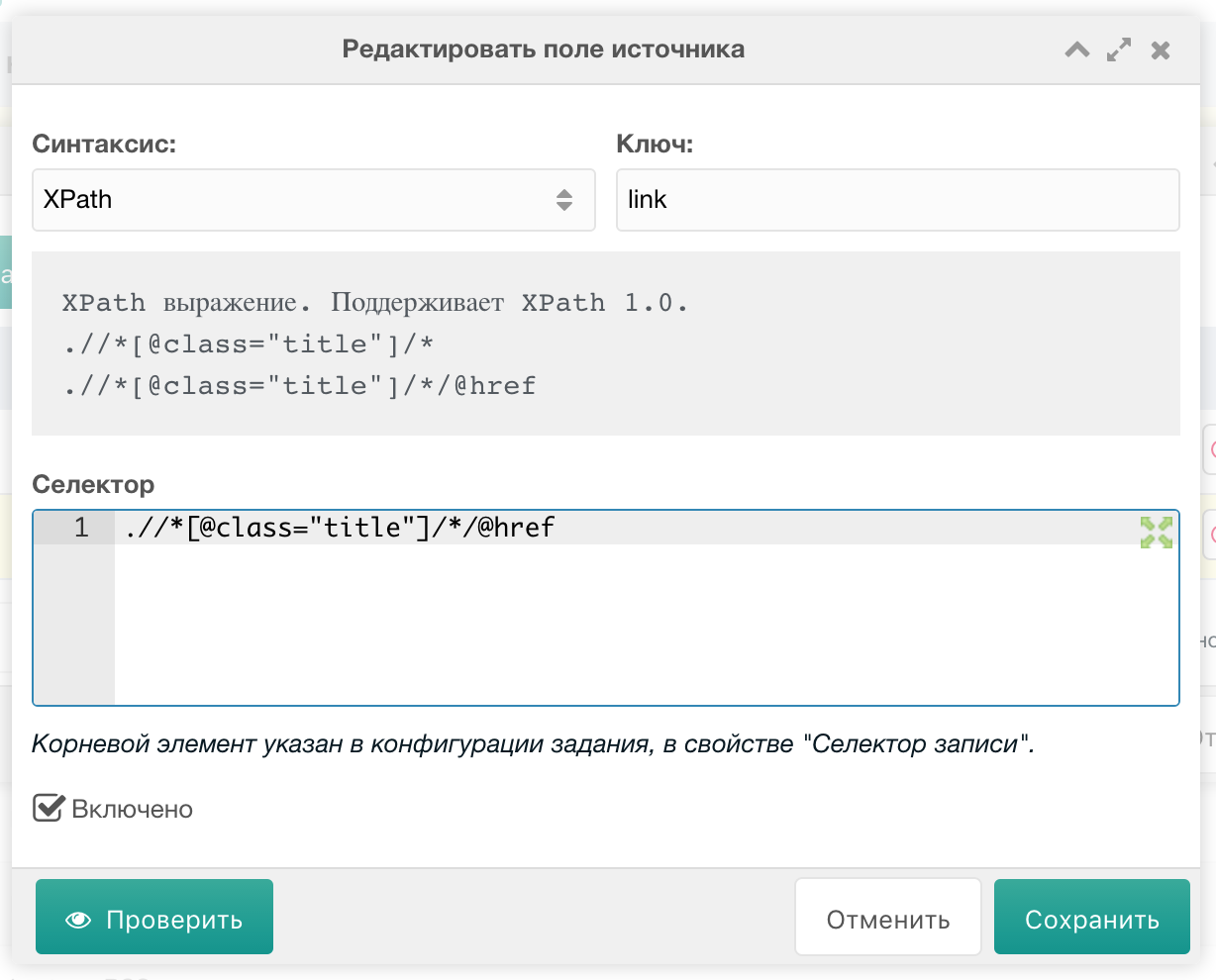
Там же можно проверить, насколько корректно парсер получает указанные нами значения. Для этого требуется нажать на кнопку с глазом:
Настройка источника для secondary задания
Тут я добавил также 2 поля: pagetitle и content.Pagetitle:
Синтаксис: CSS
Ключ: pagetitle
Селектор: h3.page-title
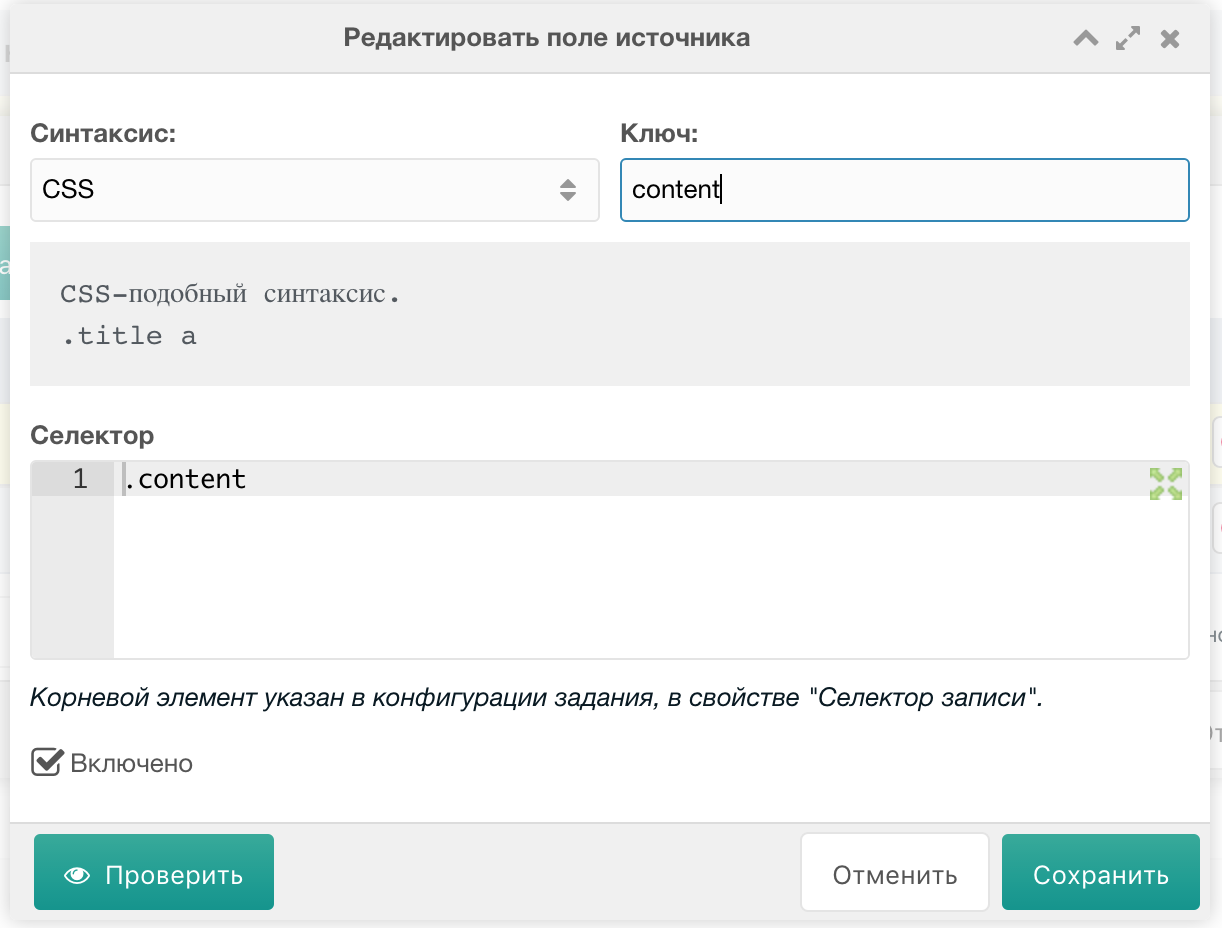
Content:
Синтаксис: CSS
Ключ: content
Селектор: .page-content
Настройка полей задания
По большому счёту тут всё очень похоже на настройку RSS задания, т.к. у нас уже есть данные из источника, которые можно просмотреть в виде распечатанного массива, кликнув по кнопке Массив сырых значений. Сейчас нам надо, опираясь на эти ключи и значения источника, правильно добавить поля для парсинга. Жмём на задании правой мышью => Поля.
Описывать подробно возможности пакета на данном этапе не буду, кому интересно, может почитать это в описании настройки RSS заданий.
Настройки полей primary задания
Здесь тоже достаточно одного поля — link, но мы добавим и поле с основным изображением поста. Выдернем это изображение из вступительной части статьи с помощью Fenom и регулярного выражения. Жмём Добавить.Link:
Системное поле: пусто
Поле в источнике: link
Значение по-умолчанию: пусто
Introtext: (запишем сюда изображение)
Системное поле: Resource.introtext
Поле в источнике:
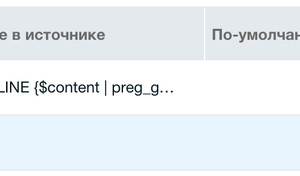
@INLINE {$content | preg_get : '!https?://.+\.(?:jpe?g|png|gif)!Ui'}Теперь в таблице добавленных полей задания у поля link кликаем на звезду (поле должно стать оранжевым) и на соседнюю кнопку. Откроется окошко добавления связанного задания. Там есть сноска, продублирую:
1) Убедитесь, что выбранное поле действительно является ссылкой.
2) При парсинге эта ссылка будет передана в задание, которое вы выбрали ниже.
3) Из выбранного задания будут получены все поля для создания объекта.
4) Полученные поля перезапишут аналогичные поля из текущего задания.
В поле Принимающее задание выбираем MODX.pro (Secondary). Таким образом, текущее задание (Primary) передаст УРЛ из поля link в задание (Secondary). Жмём Сохранить. Поле link в таблице подсветится синим цветом:

Настройки полей secondary задания
Тут добавляем 3 поля: pagetitle, content и published.Pagetitle:
Системное поле: Resource.pagetitle
Поле в источнике:
@INLINE {$pagetitle | preg_replace : '! \<sup class.*!ui'}Content:
Системное поле: Resource.content
Поле в источнике: content
Значение по-умолчанию: пусто
Published:
Системное поле: Resource.published
Поле в источнике: пусто
Значение по-умолчанию: 1
Итого
Компонент успешно развивается и будет развиваться, обрастая всё новыми плюшками. Планов много, гораздо больше, чем времени на их реализацию. Тем не менее, предложения об улучшениях принимаются с радостью.
P.S.: Следующим шагом будет внедрение возможности путешествия по страницам.
P.P.S.: Компонент успешно вырос из логотипа, надеюсь modstore заметит это. :)
Комментарии: 46
Авторизуйтесь или зарегистрируйтесь, чтобы оставлять комментарии.
АнтонНо, кроме этого, хорошей мотивацией к покупке дополнения (для меня точно) станет публикация кейсов (практической выгоды — трафика на сайт) от использования ХParser.
В ресурсе в ТВ или в любых других полях, хранятся ссылки, к примеру 3.
Запуск по крону раз в день парсинга этих ссылок для каждого ресурса.
Промежуточные результаты парсинга нужных полей (для простоты будет по 1 полю для источника, то есть ещё 3 тв или других полей) записываются в эти 3 поля.
И по окончанию парсинга ссылок каждого ресурса запускается сниппет, который уже будет обрабатывать промежуточные результаты.
Не нужно, чтобы компонент все эти действия делал, а нужна возможность управлять им в этой цепочке действий.
www.tss.ru/bitrix/catalog_export/yandex_800463.xml
Базовый тег ленты: offers
Базовый тег записи: offer
Вот что получаем в качестве данных записи:
Я заведомо сократил список параметров, т.к. получалась простыня. Также убрал весь код из параметра «Полное описание»…
Дальше эти данные можно обработать при помощи Fenom и вставить в нужные поля в MODX.
Например, у меня агрегатор кредитов от различных банков, нужно каждый день парсить актуальные данные с html страниц банков, ориентируясь по селекторам, собирать проценты, условия, и выводить в таблице сравнения.
Или агрегатор квартир в Москве, каждый день парсить сайты застройщиков, получая из нужного селектора html актуальные цены, количество оставшихся страниц и так далее
Скажите, какие условия должны быть у сайта с которого парсим?
carcopy.ru/export/integration_site/66803_1VSD.xml
1. Есть ресурс с артикулом 1102 (был создан вручную)
2. Есть xml файл с полем model и значением 1102, а также полем price со значением 100
3. В настройках парсера у поля model ставлю звездочку, делая его уникальным полем
Если я запускаю парсер и убираю галку в поле «Создавать новые записи» (Скрин yadi.sk/i/n4BheOzy_V5GQg), то после запуска вижу, что обновлено 0 ресурсов.
Я что-то делаю не так или парсер не может обновлять уже существующие ресурсы в minishop?
Как мне правильно записать селектор записи для основного задания и парсить ссылку для подчиненного?