elementSync - Еще один способ разработки MODX-приложений в IDE
Привет.
Этот элемент можно считать вторым кусочком компонента который я описал на статью одну пониже, а можно рассчитывать как отдельную тузлу. Предыстория такова: Я не использую файловые сущности pdoTools, идеологически считаю что транспортные пакеты это отличный способ для разработки компонентов, но не сайтов. Так же Gitify меня не вдохновил. Думаю имею на это право :)
Более того — частенько приходится не создавать что-то новое на MODX, а редактировать существующее. И все это нужно а) каким-то образом версионировать б) разрабатывать используя удобные инструменты в IDE. Много времени назад я использовал для этого gitmodx и он меня в целом устраивал. Но есть нюансы, которые мне категорически не нравились.
Первое — Gitmodx хакает системные файлы MODX и подменяет себя в качестве парсера. Это плохо, но в целом ничего страшного в этом нет. Но все таки бесит. Второе — Gitmodx не мапит объекты в базе, а следовательно там где нужно выбрать элемент который MODX ищет в базе — невозможно по определению. Например, шаблон письма для клиентов minishop2 приходилось создавать в админке так или иначе. Третье — исходя из второго пункта, получить массив всех чанков в системе так же трудно, т.к половина из них это файловые сущности, а половина — в базе. Грустно, хотя за всю практику мне не приходилось этого делать.
Что я предлагаю?
Я накидал небольшой файлик, который делает двустороннюю синхнронизацию чанков, сниппетов, шаблонов и плагинов в системе.
Исходный код можно почитать по ссылке: тыц
Код я буду править и добавлять что-то новое по мере своих потребностей, а так же буду его немного менять так как не все реализации что я описал мне нравятся.
Итак, код который вы видите выше я расположил в папку core. Назвал его я sync.php. Расположил там, потому что хочу и потому что вы при установке, обычно, закрываете эту папку от внешнего доступа, что позволяет добавить некоторый элемент безопасности.
В корне сайта я создал вот такую вот структуру папок:
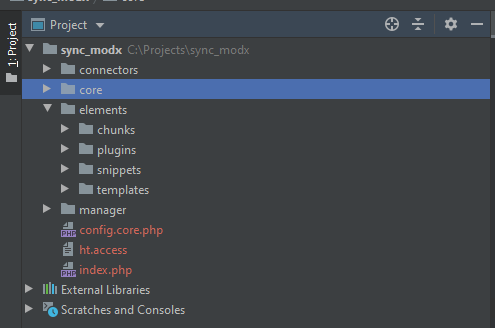
В дальнейшем вы можете версионировать только папку elements и все входящие в нее папки.
Дисклеймер: Перед тем как мы продолжим, я хочу описать сценарии, при которых я крайне нерекомендую использовать это решение:
Небольшое видео о работе: тут
(почему-то не удалось встроить)
Есть вопросы? Задавайте, отвечу.
Так же я всегда рад донатам на пиво и прочие принадлежности.
Спасибо!
Этот элемент можно считать вторым кусочком компонента который я описал на статью одну пониже, а можно рассчитывать как отдельную тузлу. Предыстория такова: Я не использую файловые сущности pdoTools, идеологически считаю что транспортные пакеты это отличный способ для разработки компонентов, но не сайтов. Так же Gitify меня не вдохновил. Думаю имею на это право :)
Более того — частенько приходится не создавать что-то новое на MODX, а редактировать существующее. И все это нужно а) каким-то образом версионировать б) разрабатывать используя удобные инструменты в IDE. Много времени назад я использовал для этого gitmodx и он меня в целом устраивал. Но есть нюансы, которые мне категорически не нравились.
Первое — Gitmodx хакает системные файлы MODX и подменяет себя в качестве парсера. Это плохо, но в целом ничего страшного в этом нет. Но все таки бесит. Второе — Gitmodx не мапит объекты в базе, а следовательно там где нужно выбрать элемент который MODX ищет в базе — невозможно по определению. Например, шаблон письма для клиентов minishop2 приходилось создавать в админке так или иначе. Третье — исходя из второго пункта, получить массив всех чанков в системе так же трудно, т.к половина из них это файловые сущности, а половина — в базе. Грустно, хотя за всю практику мне не приходилось этого делать.
Что я предлагаю?
Я накидал небольшой файлик, который делает двустороннюю синхнронизацию чанков, сниппетов, шаблонов и плагинов в системе.
Исходный код можно почитать по ссылке: тыц
Код я буду править и добавлять что-то новое по мере своих потребностей, а так же буду его немного менять так как не все реализации что я описал мне нравятся.
Итак, код который вы видите выше я расположил в папку core. Назвал его я sync.php. Расположил там, потому что хочу и потому что вы при установке, обычно, закрываете эту папку от внешнего доступа, что позволяет добавить некоторый элемент безопасности.
В корне сайта я создал вот такую вот структуру папок:
В дальнейшем вы можете версионировать только папку elements и все входящие в нее папки.
Дисклеймер: Перед тем как мы продолжим, я хочу описать сценарии, при которых я крайне нерекомендую использовать это решение:
- У вас тестовая версия сайта расположена на виртуальном хостинге. Не надо. Скорее всего вам не хватит памяти для выполнения скрипта. Поднимите локальную версию на вашем компьютере. Могу посоветовать использовать Docker. Готовый и простой конфиг с TODO я уже сделал для вас: тыц
- У вас нет доступа к SSH и вы собиратесь выполнять код в браузере. Вообще не дай бог. Лимитов веб-сервера вам не хватит еще абсолютно точнее, нежели памяти.
данная команда перенесет все текущие элементы сайта в статические и аккуратно положит вам в папочки выше.php sync.php import
данная команда наоборот запушит все изменения на сервер в виде статических файлов. Вы можете изменять и делать с ними все что захотите. Важно — прочитайте документацию по статическим файлам, чтобы у вас не возникало вопросов с кешированием.php sync.php export
это сырой запрос в базу, который отлинкует статический файл, и у вас останется версия та, что замапилась в базеphp sync.php deploy
Небольшое видео о работе: тут
(почему-то не удалось встроить)
Есть вопросы? Задавайте, отвечу.
Так же я всегда рад донатам на пиво и прочие принадлежности.
Спасибо!
Комментарии: 50
Авторизуйтесь или зарегистрируйтесь, чтобы оставлять комментарии.
Вопрос! Я столкнулся с этим когда пытался использовать gitmodx Зернова. У него тоже есть скрипт для перегонки чанков (и не только с базы в файлы) но был такой глюк (ну или скажем недочет). Если чанки в базе названы корректно (одним словом и латинскими буквами) то все ок. Но мне иногда приходят на обслуживание созданные кем-то сайты, где чанки названы к примеру так — «слайдер на главной странице» — тоесть киррилицей и в несколько слов и modx это позволяет. Но при переводе это в файлы — вместо названия «кракозябры» и плюс скрипт в gitmodx удалял после этой операции данные из базы. И ты остаешься с файлом, который уже не знаешь как назывался и не можешь его использовать.
В общем просто проверьте на такую возможность.
Поверил твой кейс — работает и на кириллице )
Сайтики на MODX деплоить в докере не стоит)
1) Вам присылают проект, а у него конфигурация писалась на nginx, а у вас на машине развернут апач или наоборот, без докера вам придется переписывать конфиги под свой сервер, а конфиги бывают ой какие не простые
2) Вам присылают проект, а там скажем очереди лежат в Redis, у вас на машине нет редиса, без докера вам пришлось бы его устанавливать, настраивать и т.д. и стоит оно того скажем ради одного проекта где работы на пол часа?
3) У вас на машине php7.1, а в проекте который вам прислали в одном из пакетов минимальная версия php — 7.3, опять же вам нужно доустанавливать 7.3 на свою машину со всеми модулями только чтобы развернуть этот проект
В основном докер решает такие проблемы в мире PHP, все что он делает по сути — это запускает на вашей машине — виртуальную и конфигурирует ее в соответствии с проектом, это настолько облегчает как разработку, так и деплой, что люди сознательно идут на уменьшение производительности храня продакшен в контейнерах
В проекте логи хранятся в MongoDB,
Новая часть проекта в PostgreSQL,
А старая часть проекта в Mysql
При этом выпилить что то одно хотя бы даже временно естественно не вариант, т.к. все ломается. Без докера мне пришлось бы настраивать у себя MongoDB и PostgreSQL, разбираться как это сделать и тратить возможно ни один час просто чтобы развернуть проект, хотя работа, которую я должен сделать вообще никак не связана ни с монгой, ни с постгрессом
Нужно наверное заняться практикой и много вопросов отпадет.
Что я не понимаю
— все таки это не виртуальная машина, а виртуальный контейнер и внутри его нет операционной системы. Контейнер использует ядро гостевой операционки. Но при этом внутри контейнера есть своя файловая система. По крайней мере я так сужу из ответов, которые получил задавая комменты на ютубе. То как знать какая именно внутри файловая система? Какие там есть директории и так далее. И плюс зачем тогда существует докер образ Ubunty? Тоесть при запуске этого образа развернется полноценная операционная система? Со своей файловой системой, своими демонами, процессами и так далее? У меня есть ubuntu server установлен на физическом сервере. Установлен docker и запущен контейнер ubuntu. У меня есть возможность подключится к виртуальной ubuntu? по ssh или как либо по другому?
— насколько я понимаю, при остановке запущенного контейнера все данные в нем теряются. Ведь контейнер создается из образа и если произошел сбой или же запланированная остановка контейнера, то новый контейнер запуститься из того же образа и будет девственно чист. И как тогда работают контейнеры с базами данных? Да я вижу что к контейнеру можно примонтировать внешнюю директорию и хранить данные на ней, но получится что вам каждый подключаемый в свой проект образ (вернее создаваемый на нем контейнер) придется очень долго и нудно конфигурировать, подгоняя под реалии операционной системы на которой он запущен (к примеру даже у линуксов не у всех структура и название директорий операционной системы одинакова). Тоесть есть три ветки продуктов линукса- основанные на redhat. arch и debian. И они во многом отличаются. Если на одном сервере установлена centOS (родитель redhat) а на другом Ubuntu (родитель Debian) то их файловые системы хоть и схожи но не идентичны. Но это ладно, но ведь сервер может работать и на windows, а docker тоже может работать на windows. И как тогда запустить контейнер с приложением, если у него в докер файле например пути прописаны /usr/bin и содержаться команды для оболочки bash
— от имени какого пользователя это все работает? Как и кто это контролирует? К примеру я недавно испытывал технические проблемы на одном сервере, что возникала ошибка при работе с сессиями в php. Оказалось что в конфигурации php указывается директория где будут хранится файлы сессий и пользователь от имени которого запускался интерпретатор php не имел прав на запись в эту директорию. Или к примеру веб сервер apache запускается от имени пользователя www-data и только он может полноценно работать. А кто пользователь внутри контейнера? Тот кто его запустил? Но если судить по документации на офф сайте то докер работает из под root а значит мы все процессы запустим от root?
А тут уже как настроите и какую ОС выберете
Именно, при том, частой практикой является своя ОС под каждый модуль, т.е. например nginx + php-fpm в одном контейнере, mysql в другом, redis в третьем
Да, также как и выполнить внутри любую команду извне
Да, если они не смонтированы извне
да, через интерфейс докера docker exec
У любой базы данных есть физические файлы) Вот их и монтируют
Как правило в компаниях работают всегда на одном и том же стеке и есть уже готовые образы лежащие где то на сервере обновляемые удаленно девопсами под каждый стек, они конфигурируются один раз и дальше просто поддерживаются, а проекты извне на доработку обычно приходят уже с конфигурацией и это не ваша забота, а забота заказчика если у него в контейнере что то не работает)
Да, но в целом это забота девопсов, ну или вас, если вы собрались делать свой собственный и не повторимый образ, в любом случае «наружу» торчат только файлы проекта, иногда конфигурации nginx/apache и файлы баз данных
Контейнер настраивают обычно при старте разработки проекта, если проект готовый, вам его нужно просто развернуть одной командой и не зависимо от вашей ОС, внутри все директории и оболочки будут те, что предусмотрел и продумал девопс, в целом докер для этого и нужен, чтобы приложение не зависело от окружения разработчика
Опять же, как настроит разработчик, но чаще всего от виртуального рута, вам нужно прокинуть собственного пользователя в виртуальный рут, для этого существует команда docker login, это делается один раз
Т.к. в контейнере пользователь обычно один, он виртуальный и от его имени все работает, такая проблема в принципе исключена
Фух :) Вроде бы на все ответил, но я могу в чем то ошибаться, у нас в компании есть devops которые отвечают за такие вещи, нам разработчикам только и остается что в новые проекты уже подтягивать один из готовых контейнеров, я не гуру докера но вроде бы на ваши вопросы ответил правильно)
По сути если хорошо владеете линуксом, то и с созданием своего контейнера проблем возникнуть не должно, просто начните пробовать, тут теория в целом не нужна, а если вы ни разу не разворачивали даже локальное окружение на линуксе, то тут стоит начать с изучения линукса, а не докера. Но в целом у нас в компании есть люди, которые вообще в докере никак не понимают и никогда даже локальное окружение не разворачивали, однако это не мешает им быть хорошими программистами и эффективно его использовать, просто не лезут в конфиги, а используют готовое. И без личного девопса в интернете образов полно на любой вкус и цвет
Добавить особо не чего, единственно что смущает — в большинство случаев я к примеру и не знаю где лежат файлы той же mysql базы данных. Даже если я сам админю сервер и поднимаю все нуля, то я делаю apt install mysql-server и все, я не выбираю куда сложить файлы. А выходит чтобы использовать в докере mysql то придется серьезно повышать уровень знаний, иначе на первый взгляд покажется что все работает, пока контейнер не упадет и все данные из него просто пропадут.
В CMS докер — это абсолютно не нужный оверкилл, сайты на CMS как правило так часто не дорабатываются, они не зависят от внешних пакетов, а доработки в основном такого размера, что минусы докера никогда не окупятся сэкономленным временем от его использования
Или процедура такая: я сначала делаю импорт, меняю как надо файлы, синкаю их с дев-сервером, например, а после этого делаю экспорт, который эти файлы фигачит обратно в базу? Просто не понятно, к чему там танцы с переводом на статику?
Статические файлы можно редактировать из под IDE, т.к они физически находятся на диске.
Что делает функция Deploy — описано
А вот статические файлы MODX — это жуть.
При чем это жуть настолько, что тебе может даже не хватать памяти для рендера страницы)))
можно создать файл без расширения в котором написать:
тогда можно будет запускать скрипт уже через команду
А если в IDE создать доп папку в чанках и закинуть туда tpl-ки, они не будут синхрониться?
Иначе, работает только по твоей структуре без группировки?
У меня не пошла синхронизация из созданной папки. Когда перенес, все сработало.
UPD. Скрипт зашел. А нельзя добавить ТВ через него?
Читал, про них отзывы. Но если бы была возможность хотя насоздавать их и рассортировать, а потом зайти в админку и настроить, уже легче жить сразу.
Я просто не совсем понимаю зачем.
Добавить, в принципе совсем не проблема.
Я к тому, что они же ни на, что не влияют. Все равно все в БД.
Или я не совсем правильно понял основную мысль?!
ТВ-шки. Мне показалось это удобнее.
Хотя сейчас зашел в админку, посоздавал ТВ-шки и сам задумался.
С другой стороны, имея возмость скопипастить название TV удобнее в код вставлять. Не нужно заходить в браузер. Как вариант.
по темене по теме для разработчиков на idea…Медленно, но уверенно изучаю idea плагонизацию, в отдельных проектах юзаю феном, поэтому сейчас занимаюсь разработкой плагина в idea, который будет адекватно работать с reformat, синтаксисом, быстрым линком к шаблону (через ctrl) из extends, include и т.д. Вообщем полный фарш…
С феном то все понятно, его закончу, но вот мысли у меня сделать отдельно такой плагин и для modx, который бы работал бонусом со всеми выше перечисленными объектами (шаблоны, чанки) напрямую с бд. Как это сделать удобно — без понятия, но вот прочитав вашу идею с «tmp» файловым хранилищем, который синхронизируется с бд — у меня появилась мысль синхронизацию перетащить полностью на phpstorm (idea)… Т.е. по факту шторм будет напрямую работать с бд, минуя файлики modx… (Это пока мысль)
Собственно сам вопрос, на сколько это было бы актуально, и сможем ли мы сообществом сделать адекватную модель работы такого плагина?
Мне лично только её не хватает при работе из IDE, синтаксис MODX уже давно не использую.
P.S. Есть вот такой древний плагин для Fenom. Он очень сырой, но может чем-нибудь пригодиться.
Создал проект (в шторме), получил экспорт в виде тех же файлов, отредактировал что нужно, и в одно нажатие импорт ушел…
Тогда да.
Мне кажется прямой связи делать не нужно. Если бы я проектировал такое ПО, думаю я бы средствами idea формировал бы карту элементов на условном YAML и в дальнейшем бы двигался по файлу не затрагивая базу в принципе.
А вот с базой ты погорячился. Напрямую работать можно только при условии, что сервер MySql доступен снаружи. Часто такое бывает?
А вообще тема нужная.
Для плагинов Idea этого, как оказалось, и не нужно. В привычном софте jetbrains, после шторма, любой ооп язык легко поддается чтению и навигации. Да, безусловно, есть нюансы в каждом языке, но я обычно опираюсь на готовый код самого JB. Например, для плагина феном я местами дублировал функционал плагина smarty, но разумеется, со своим сахаром. На хабре недавно статья вышла от баду, там ребята вообще пилят свой плагин под компанию. Но в целом, да… главное найти на это время.
в 90% случаев, с которыми я сталкивался — да, внешний доступ к бд был.
где-то было что-то похожее про импорт или экспортвот оно. Там это всё в консольке сайта делается, ибо у неё есть фича встроенная, но можно это вручную повторить, главное — идея.Но не кажется что слишком много телодвижений, когда можно просто создать тестовую версию там, где у тебя хотя бы 128 мегабайт пхп лимита есть?)
А там уже не нужно столько памяти