а расскажите мне про Github и программирование с git
Если у кого-то найдется время и возможность, поделиться своим опытом и ответить на мои вопросы, буду благодарен.
Я обычно стараюсь максимально подробно изложить вопрос и проблему, но часто вижу, что просто сбиваю людей с толку. И сейчас я тоже вычертил много диаграмм, продумал текст, но решил повременить.
Попробую кратко.
Я был очень много лет единственным программистом в компании, сейчас стоит задача наладить работу для 4-5 разработчиков.
Нюансы. Наша компания только 20 процентов сайтов разрабатывает сама. Остальные 80 — это проекты кем-то когда-то сделанные, на разных CMS и фреймворках, которые уже по 10 лет работают на захудалых виртуальных хостингах.
Цель. продумать схему работы, при которой сам сайт (production) будет максимально защищен от ошибок, при этом несколько разработчиков смогут так или иначе влиять на его код, постоянно внося изменения.
Я специально удалил из этой диаграммы все связи.
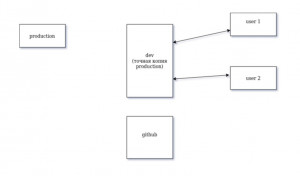
чтобы не навязывать своих идей.
Есть сайт, который трудится на хостинге заказчика (не факт что там даже есть git но пока не будем о печальном). Есть наш сервер. У каждого проекта планирую свой сервер, поскольку сайты все разные (есть такие которые требуют php 5.2 а есть такие которые в качестве операционки используют os bitrix). Есть два разработчика, которые могут взаимодействовать с сервером dev (я предполагаю, что взаимодействие будет через возможности ide работу с удаленными серверами)
есть аккаунт на github.
Как максимально правильно связать это в жизнеспособную систему? Где должны быть инициированы репозитории? Потому как из моих скудных знаний о git я знаю, что клонировать репозиторий можно только в пустую директорию, а значит первую инициацию нужно проводить на сервере production…
А теперь часть вопросов о сервисе github.
Вот на этой странице расписаны цены и некие ограничения.
github.com/features/packages#pricing-details
Я правильно понимаю что 500 мегабайт это суммарный объем для всех репозитариев на этом аккаунте? Просто не раз слышал от разработчиков, что они хранят в репозитарии полностью весь сайт и как-то это странно. Да я понимаю что такой глупой специфики как у нас еще поискать (работать с чужими и старыми проектами, весом иногда в 150 гигабайт, потому что одному Богу известно что хранится в этих миллионах директориях самописного сайта).
Что за ограничения в передаче данных, которые тоже описаны на этой странице?
github.com/features/packages#pricing-details
Data transfer out within Actions
и
Data transfer out outside of Actions
Старался очень кратко, но вышло как всегда. В общем буду рад советам и опыту.
ps Советы по поводу — нанять девопсов и системных администраторов безусловно правильные и я с ними уже заранее согласен, но мир не идеален а мы компания не того уровня. Уже то что после того как я 4 года один вел около 30-40 проектов и мы решились взять кого-то еще — уже неимоверный шаг. Не все сразу)
Я обычно стараюсь максимально подробно изложить вопрос и проблему, но часто вижу, что просто сбиваю людей с толку. И сейчас я тоже вычертил много диаграмм, продумал текст, но решил повременить.
Попробую кратко.
Я был очень много лет единственным программистом в компании, сейчас стоит задача наладить работу для 4-5 разработчиков.
Нюансы. Наша компания только 20 процентов сайтов разрабатывает сама. Остальные 80 — это проекты кем-то когда-то сделанные, на разных CMS и фреймворках, которые уже по 10 лет работают на захудалых виртуальных хостингах.
Цель. продумать схему работы, при которой сам сайт (production) будет максимально защищен от ошибок, при этом несколько разработчиков смогут так или иначе влиять на его код, постоянно внося изменения.
Я специально удалил из этой диаграммы все связи.
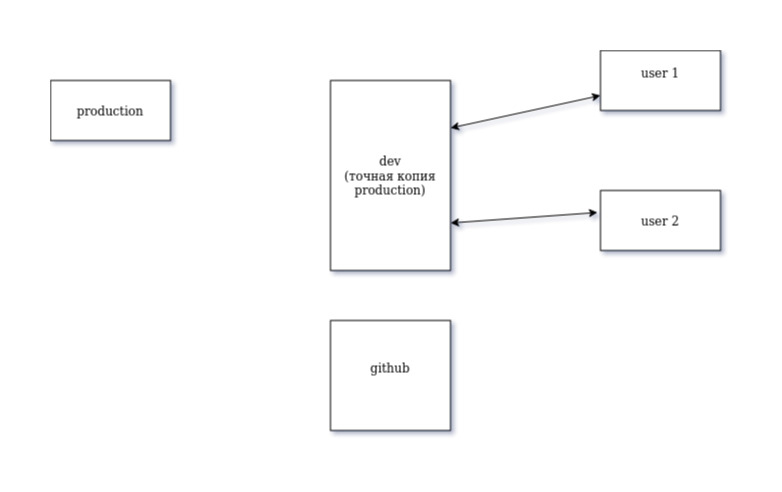
чтобы не навязывать своих идей.
Есть сайт, который трудится на хостинге заказчика (не факт что там даже есть git но пока не будем о печальном). Есть наш сервер. У каждого проекта планирую свой сервер, поскольку сайты все разные (есть такие которые требуют php 5.2 а есть такие которые в качестве операционки используют os bitrix). Есть два разработчика, которые могут взаимодействовать с сервером dev (я предполагаю, что взаимодействие будет через возможности ide работу с удаленными серверами)
есть аккаунт на github.
Как максимально правильно связать это в жизнеспособную систему? Где должны быть инициированы репозитории? Потому как из моих скудных знаний о git я знаю, что клонировать репозиторий можно только в пустую директорию, а значит первую инициацию нужно проводить на сервере production…
А теперь часть вопросов о сервисе github.
Вот на этой странице расписаны цены и некие ограничения.
github.com/features/packages#pricing-details
Я правильно понимаю что 500 мегабайт это суммарный объем для всех репозитариев на этом аккаунте? Просто не раз слышал от разработчиков, что они хранят в репозитарии полностью весь сайт и как-то это странно. Да я понимаю что такой глупой специфики как у нас еще поискать (работать с чужими и старыми проектами, весом иногда в 150 гигабайт, потому что одному Богу известно что хранится в этих миллионах директориях самописного сайта).
Что за ограничения в передаче данных, которые тоже описаны на этой странице?
github.com/features/packages#pricing-details
Data transfer out within Actions
и
Data transfer out outside of Actions
Старался очень кратко, но вышло как всегда. В общем буду рад советам и опыту.
ps Советы по поводу — нанять девопсов и системных администраторов безусловно правильные и я с ними уже заранее согласен, но мир не идеален а мы компания не того уровня. Уже то что после того как я 4 года один вел около 30-40 проектов и мы решились взять кого-то еще — уже неимоверный шаг. Не все сразу)
Комментарии: 28
Авторизуйтесь или зарегистрируйтесь, чтобы оставлять комментарии.
Изначально её придумал Линукс Торвальдс для разработки ядра Linux, и система получилась настолько удачной, что теперь является самой популярной Version Control System.
Github, как следует из названия — просто удобное место для хранения репозиториев Git. Есть еще и другие сервисы, в частности Gitlab, который может быть установлен на собственный сервер.
Основное преимущество Git — простейшее создание новых веток и последующее их слияние, с разрешением конфликтов. Это очень удобно, когда несколько разработчиков делают разные задачи — просто создал свою ветку, отправил pull request в репозиторий, а кто-то один потом сливает все ветки в master перед тестированием и релизом. Собственно, именно так сейчас происходит разработка MODX.
Ну а когда всё слито и проверено — кто-то один может выгрузить новую версию в продакшен напрямую со своего компа. Если изменений много, можно писать какие-то скрипты миграций.
На самом деле, вопросов по работе именно с Git быть не должно — там всё просто, если почитать и подумать. А вот как засунуть в него сайт на MODX или Bitrix, вот это может быть проблемой, да.
Лично у меня всё на файлах, пользовательский контент, картинки и прочее я не синхронизирую и не храню в VCS, для этого есть бэкапы. А в Git только рабочий код, что делает репозитории очень небольшими. Лично я в лимиты Github ни разу не упирался.
Я наверное написал неудачный заголовок, мол расскажите что такое git и github и вы честно и полно рассказали.
Нет, конечно я знаком и с программой git, и с историей ее создания и знаю что такое github по своей сути. Просто миллионы людей рассказывают, что постоянно пользуются системой контроля версий именно для деплоя, для синхронизации сайтов, а я вот как и вы считаю, что она для этого как минимум неудобна. Это именно инструмент для совместной разработки, вот почему я и не пользовался ей в работе, потому что я все разрабатывал сам.
Я совершенно с вами согласен, что не нужно хранить картинки на гитхабе и прочую лабуду. Но тут есть один фактор — вы можете добавить в гитигнор необходимые директории и так далее только если вы сами делали этот проект и его архитектуру, то есть вы точно знаете что и в какой директории у вас находится. А в случае если берут на обслуживание проект, который уже весит 100 гигабайт, в нем 100 000 директорий бесконечно вложенных друг в друга, то практически невозможно определиться, какие директории добавлять в гит, какие исключить. К примеру видишь директорию с названием images, думаешь — обязательно нужно заигнорить, картинки то нам зачем. А потом в процессе разработки сталкиваешься с тем, что в этой директории кроме 70 000 изображений есть еще и два php файла, которые важны и нужны для решения задач. Начинаешь городить костыли, как теперь их добавить. И хорошо если их два и нужно внести исключения в файл gitignore а если их 40… А еще хуже если ты наоборот случайно закунул на гитхаб директорию, которая была вложенная в десяток других, просто потому что ты о ней ничего не знаешь, а в ней — 30 000 pdf файлов. Короче говоря да, я считаю что git удобный инструмент именно для совместной работы над НОВЫМ кодом.
Но тем не менее, стоит задача продумать такую систему, которая даст возможность 3-4 разработчикам, работать с кодом сайта на сервере dev (копией production) ничего даже не зная о сервере production. После достижения желаемого результата эти изменения должны быть перенесены на сервер production. Как бы вы решили эту задачу? Вот вы написали что git на production не используете. А как тогда? Вот к примеру результат работы двух разработчиков (пока не будем вникать как мы этого добились) лежит в виде кода на github. Как его поместить на production? Что скачивать zip архив и по ftp заменять файлы?
Да и вопросов то конечно куча, и исходят они скорее всего от моей невежественности, но на то «мировой разум» и существует, чтобы каждый не изобретал свой велосипед.
Просто хотелось бы услышать кто какую схему использует или же предложит для решения этой задачи.
Я вот например в своей схеме склоняюсь к мысли, чтобы запретить разработчикам иметь локальный на своем компьютере репозиторий гит, чтобы с файлами сервера dev они работали исключительно через возможности phpstorm (настроить передачу при сохранении), а git был только на сервере. И мол если добились результата, то подключились по SSH, закомитили изменения и вытолкнули на гитхаб. Но не знаю насколько это разумно в плане мирового опыта)
Плюс еще нужно мне изобрести универсальный метод быстрой синхронизации. В случае к примеру если разработчики убили сайт на dev нужно быстро развернуть им свежую версию, максимально приближенную к pro. Собираюсь делать это написанием bash скриптов, которые будут делать дамп базы, сжимать в zip все файлы, а на другом сервере скрипты будут скачивать эти файлы, распаковывать и так далее. Но возможно в мире существуют решения разумнее?
Обычно кто-то один сливает все pull-request в основную ветку. Он же может и выгрузить эту ветку на основной сервер.
Тут вообще без разницы, как именно доставить файлы: через ftp, sftp, git, голубинной почтой — главное, чтобы было выгружено именно то, что вы сделали, и больше это никто в обход Git не трогал руками.
Это противоречит самой идее Git — делать ветки на любое изменение, а потом их сливать в одну основную.
Git это нифига не для деплоя проекта, это для разрешения конфликтов и хранения истории изменения.
Если 2 разработчика, которые делали разные фичи, поменяли один файл — вы как это будете разрешать при их «закомитили изменения и вытолкнули на гитхаб»? Они сами всё будут в master пушить, что ли?
Нет, у каждого свой dev-сайт, свой копия Git репозитория, в которую он забирает изменения из основной, и из которой отправляет в основную свои изменения. А кто-то главный собирает их все и сливает в основную ветку, которая потом уже и выгружается в production.
и можно работать. Но вряд ли получится такое прикрутить к MODX или Битрикс.
Просто в моей голове все примерно так выстроено — разработчик работает с кодом, через ide. Сохраненные, измененные или созданные им файлы попадают на сервер dev. Там лежит полноценная полная копия, которую можно открыть через браузер. Разработчик работает до тех пор, пока не решил задачу. Стучится кому-то кто ответственный и говорит — сделано, проверяйте. Ответственные люди проверяют функционирование и говорят — супер. иди комить и пуш на гитхаб. После того как работающий когд оказался на гитхабе он голубиной почтой передается на продакшен.
Именно поэтому меня смущает фраза
выделенный сервер на 100 гигов чтобы развернуть один dev сайт будет обходится в десятки тысяч в месяц, а держать три таких сервера по одному для каждого разработчика — это невозможно финансово (ну кроме того и технически сложно)
С чем именно связано то, что вы говорите, что нужно для каждого разработчика свой dev -сайт?
Я поэтому и хочу, обсудить именно схему такой работы.
Предположим разработчик проснулся утром, видит в трелло задачи по этому проекту.
Он подключается к серверу по ssh на всякий случай стягивает ветку мастер с гитхаба на сервер dev. Приступая к работе создает и переключается на ветку новой задачи. Может закрыть ssh. перейти в ide и на всякий случай синхронизировать файлы и в ней. (git репозитарий не вытаскивая, тоесть на локальной машине никакого git) Работает пока не решит задачу (на его взгляд) Идет снова на сервер делает коммит в новую ветку. Зовет проверяющего. сайт dev тестируется и если все ок то разработчик или новую ветку закидывает на гитхаб (и тогда кому то придется их еще объединять) или (ведь задача уже проверена), сам сливает ее с master. На этом его работа окончена. Кто-то другой каким-то образом данные из ветки master на гитхабе переносит на production.
Какие проблемы ждут меня при такой схеме работы?
НО!
Я наверное не указал главного, простите.
Одновременно два разработчика не будут работать.
У нас около 40 проектов и планируется нанять около 3-4 человек, за каждым из которых будет закреплено около 10 его проектов. Чтобы он их изучил и только он с ними работал.
Тоесть основная задача наверное не в том, чтобы продумать систему когда 4 человека одновременно работаю над одним кодом (до этого нам как компании еще лет 100 а в то время программисты уже будут не нужны) а в том, чтобы человек не мог сломать сайт production вообще никак, но мог выполнять задачи по доработкам этого сайта. Причем доработки самые разные — это не всегда прямо глобальная фича, это и — ой заказчик захотел попробовать как сайт будет смотреться если заголовки h1 станут красными)
Что реально если 5 человек работает с одним сайтом, то у каждого свой сервер со своей копией сайта?
Вы работаете с чужими и старыми сайтами, чей вес за годы жизни перевалил за десятки гигов? Мне кажется это так экономически нереально содержать 5 серверов для 5 разработчиков, и это только по одному проекту. А если проектов 40. и на каждом 5 разработчиков, то это будет 200 выделенных серверов. Стоимость одного минимум 10 00 в месяц, это 2 000 000 рублей в месяц)
И требовать от разработчиков, чтобы они докупали себе по 100 гиг под каждый проект — не имею права. Плюс локальный сервер не так просто выставить в интернет. А каким образом тогда будет происходить контроль над работой и проверка результатов, если все крутиться локально у разработчика.
Очень интересно.
Если задача следующая. Есть 40 проектов. Все они на серверах заказчика. Средний вес файлов — около 40 гигабайт на каждом.
Одному разрабу выдается 10 проектов, которыми только он будет заниматься.
Но он вообще не должен знать о существовании сайта заказчика и не иметь возможности его править. Только с сайтом dev работать и так, чтобы была возможность в любой момент увидеть этот dev сайт в браузере, проверить выполнение и потом синхронизировать данные с сервером production
Вот даже специально не упоминаю слово git
Все приведенные выше «Проблемы» — надуманы.
Маленький накопитель? Ну поставь побольше, какие проблемы то. Подключи внешний накопитель, Заведи себе отдельный компьютер в конце концов.
Нанимаемых разработчиков уговаривать не нужно. Нужно предоставлять рабочие машины. Это факт. Либо ставить перед фактом.
Вывести проект на локальной машине в сеть не так то просто? Серьезно? Это решается одной записью в hosts. Даже если я упрощаю то все сводится к готовым описанным в документации решениям.
Мы все работаем удаленно из разных стран.
Вот это круто без ироний. Буду рад если научите, но помоему это не возможно кроме случаев когда провайдер выдает разработчику белый ip, а такое огромная редкость. А в случае использования виртуальных машин все будет еще сложнее — с проброской портов с гостевой системы на виртуальную и так далее. Требовать таких умений от разработчика php я не имею права и обязан предоставить человеку удобное место для разработки.
Вы правы, я лишь исследую тему.
Я обычно больше переживаю за синхронизацию баз данных, системных настроек, лексиконов и всего того что вынужденно находится в базе.
А вообще, для тестирования кода пользовательские данные не нужны, можно их набивать через Faker.
Мы сейчас еще и до написания тестов договоримся, такими темпами.
Я не совсем понимаю, что ты понимаешь под сервером разработки. Для разработки в IDE по-любому закачиваешь проект на локалку. Тут же можешь поднять встроенный в PHP вэб-сервер. Лично я использую XAMPP. Там уже всё есть. В идеале, конечно, докер нужно осваивать. Но мне пока это не нужно.
В твоём случае, насколько я понимаю, тебе нужен механизм деплоя, а не контроля версий.
нууу… и да и нет. я например не закачиваю все все файлы, чтобы можно было прям на основании этих файлов развернуть сайт. IDE закачивает только необходимое для работы, работаю, сохраняю, файлы отправляются на сервер и уже там я смотрю результат.
Только тут нужно уточнить, что перед началом работ он забрал все изменения из общего репозитория проекта, а после этого создал новую ветку для работы в своём локальном репозитории проекта.
В основном ничего не меняется, всё у него локально.
Верно, при условии, что у каждого разработчика свой собственный dev-сервер.
Верно, и по ходу работ он делает коммиты в свою локальную ветку когда ему удобно.
Неверно. Разработчик никуда не стучится, он просто делает pull-request своей ветки в общий репозиторий, и ответственному человеку приходит уведомление об этом на почту.
Учитывая, что в Github есть раздел Issues и Projects, каждый подобный PR можно сразу привязывать к конкретной задаче, которую он решает.
Верно.
Они скачивают ветку этого разраба и тестируют на своём локальном dev-сервере. И если всё окей — то ответственный человек сливает эту ветку с основной.
После чего разраб может свою ветку удалять — она больше не нужна. Обращаю внимание, что у обычного разраба даже прав нет запушить свои изменения напрямую в master без проверки. Такие права есть только у очень ответственных людей.
Не просто работающий код. А после того, как изменилась основная ветка master, ответственный человек заходит на продакшн и делает git pull, который меняет файлы на рабочем проекте. Ну или еще как-то отправляет именно master на сервер.
Это, конечно, можно автоматизировать.
Слава Orcale, VirtualBox совершенно бесплатен. Есть еще Vagrant, Valet и прочие хорошие локальные среды разработки.
С логикой работы, которую я описал выше.
При одном общем dev-сервере никакого толку от Git не будет, это натуральный публичный дом, в котором кто угодно может порушить что угодно и никогда концов не найти.
Ты считаешь Git каким-то хранилищем готового кода, а не инструментом разработки, когда в него присылаются предлагаемые изменения, а кто-то ответственный их проверяет и добавляет в основную ветку кода.
Вот просто представь разработку ядра MODX по твоей схеме, когда десятки людей что-то делают и тестируют на одном dev-сервере. Ну бред же, так не бывает.
У каждого разраба есть своя копия ядра MODX, своя копия репозитория, и когда кто-то хочет что-то изменить — он делает pull-request, который рассматривается командой MODX и либо отвергается, либо вливается в master.
Нет никакой принципиальной разницы при разработке проекта двумя людьми, или сотнями, принцип один — из маленьких ручейков собирается основной поток.
вот такого я не знаю. По моему в командах гита такой команды нет, это какие то фишки чисто гитхабовские?
Вчера буквально видел в документации office битые ссылки. Нужно их заменить на рабочие и сделать PR.
Когда он хочет забрать изменения из основного репозитория, он делает git pull upstream. Основной репо — не его, он может оттуда только читать обновления.
Затем он делает git merge этих изменений со своим локальным репо, добавляя в него, таким образом, обновки от других разрабов и master. Это ему пригодится, чтобы начинать работу в новой ветке, базируясь на актуальном коде.
Когда он закончил работу — он делает git push в свой репозиторий. И тогда у него получается полная копия основого репо + его ветка.
И вот эту ветку он просит забрать и посмотреть владельца основного репо, через pull-request. Что есть буквально «просьба скачать».
Подытоживаем:
— есть основной репо ответственных людей с особыми правами
— есть сколько угодно копий у разрабов
— разрабы в любой момент могут забирать все обновки из основного репо себе
— эти обновки они добавляют в свои копии, и на них базируются при новой работе
— дальше они делают свои ветки и отправляют их к себе в репо
— а потом просят позырить эти правки ответственных людей
— те их забирают в свой репо
Подробнее можно прочитать на Хабре — habr.com/ru/post/125999/
Просто у кого не спрошу — первый ответ -git
а начинаешь вникать в нюансы, так вроде гит то тут и не нужен для этих целей.
То, о чём ты говоришь — это тестовый сервер, куда выкатываются изменения перед продакшеном. Там максимально полная копия рабочего сайта на текущий момент, которая обновляется с рабочего сайта перед тестированием (если так надо вообще).
Делает это всё только ответственный человек, который выкатывает новую версию. Тестировать должны специально обученные люди — тестировщики, ну или сами разрабы, если народу нет.
По итогам этих тестов могут быть еще исправления, опять тесты и вот только потом, когда на 100% всё хорошо — продакшн.
Именно отсюда шутка про «хуяк-хуяк и в продакшн!», может слышал. Это когда все стадии пропускаются, и обновка сразу пуляется на рабочий проект, желательно в пятницу вечером.
Как ты уже догадался, общий тестовый сервер к локальным серверам разработчиков никакого отношения не имеет, они туда ходят как обычные юзеры, изменить ничего не могут.
Мне даже мысли не приходило что вы под словом тестовый сервер имеете ввиду не тоже самое что dev. Просто когда работаешь сам, то рабочий процесс примерно такой. Руководство взяло какой-то сайт, сделанный 12 лет назад неизвестно кем и на чем (иногда попадается python иногда вообще C#). Я иду разбираюсь как с него сделать копию, на своем сервере и там работаю с кодом. Сервер у меня и для разработки и для тестирования (имеются ввиду конечно не тесты phpUnit или им подобные, а чисто визуальная проверка функционала, если на это отводится руководителем хоть 30 минут) и все — пошел по ftp перекинул файла на основной сайт.
И честно говоря считаю, что для одного человека больше вообще ничего не нужно. За много лет без всяких долгих тестов кода, ни один сайт я не угробил, все работают нормально, а некоторые очень успешно.
«современные» методы разработок кажутся мне часто избыточными, люди с серьезными лицами пользуются кубернетс, докерами, миллиардами всяких технологий разрабатывая крохотный сайт на 10 страниц. Хотя может я и ошибаюсь. Но спасибо в любом случае за подсказки.
Ты же спрашиваешь, как организовать работу для большего количества людей, и тут всё резко усложняется. Хоть для 10 страниц, хоть для 10 тысяч, разницы в логике никакой.
Я уже столько раз критиковал всякое модное, а потом начинал им пользоваться через пару лет, что просто промолчу.
ssh авторизация в github нужна для чего? Чтобы при работе с удаленным репозиторием не вводить каждый раз логин и пароль?
Просто столкнулся с тем, что создал ключ, подключил его к гит клиенту, установил этот ключ в аккаунт github. Все как описано по шагам здесь
help.github.com/en/github/authenticating-to-github/connecting-to-github-with-ssh
Успешно прохожу тестирование ключа, как расписано здесь
help.github.com/en/github/authenticating-to-github/testing-your-ssh-connection
однако каждый раз когда из терминального git обращаясь к удаленному origin — запрашивает логин и пароль. Может я не верно понимаю в чем суть ssh авторизации?
Есть идеи почему у меня получается такой результат?
ps наверное нужно расписать очередность действий.
есть директория. в ней инициализирован новый репозиторий git. заданы глобально email и имя пользователя. на github создан новый репозиторий. он подключен через git add remote. делаю первый коммит, делаю пуш на origin. Запрашивает логин и пароль с github что логично и ожидаемо.
Далее создаю ключ и все как описано выше. Ни на каком этапе ошибок не возникает. Прохожу тестирования ключа и тоже все ок. Делаю изменение в файле. добавляю его, создаю коммит. делаю пкш на origin и снова спрашивает логин и пароль. И так каждый раз как я пытаюсь «пообщаться» с удаленным репозитарем.