[pdoTools] Мета-теги и сниппет pdoTitle
В этой заметке объявление сразу двух новых версий, потому что они вышли с разницей в один день.
Самое интересное, пожалуй, это встроенные мета-теги у сниппета pdoPage, которые предложил Иван Климчук.
Делать ничего не нужно, просто обновитесь и на всех страницах с пагинацией появится что-то вроде

Усли у вас на странице несколько вызовов pdoPage, то нужно выбрать только один, который будет выставлять теги, а у остальных указать новый параметр &setMeta=`0`.
Второе важное изменение: теперь все сниппеты поставляются с пустым параметром &scheme, а это значит, что ссылки у них генерируются исходя из системной настройки link_tag_scheme. Конечно, вы можете указать и своё значение, как и раньше.
Сниппету pdoNeighbors добавлена возможность указания параметра &parents. То есть, теперь выводить ссылки на следующие-предыдущие страницы можно не взирая на реальное положение дел. При этом настоящие соседи документа всегда включаются в выборку.
Не знаю насколько это будет полезно, но предложение такое было.
Сниппет pdoMenu научился правильно показывать &selfClass и &hereClass для документов ссылок. Спасибо вот этому PR.
Ну и, наконец, если указан пустой параметр &titleOfLinks, то для плейсхолдера [[+title]] ссылок меню будет использовано поле pagetitle.
Первая версия сниппета находится здесь, а в pdoTools уже улучшенный вариант, с поддержкой лексиконов, чанков и &ajaxMode сниппета pdoPage.
Оценить работу можно во всех title этого сайта. А почитать документацию вот здесь.
Еще у сниппета pdoPage исправлено перезаписывание скриптов и стилей вызываемых сниппетов. Например, теперь нормально будут грузиться файлы ms2Gallery при вызове его в pdoPage.
Также при включенном &ajaxMode pdoPage вызывается событие pdopage_load, которое можно использовать для обработки навигации:
Обновляемся, тестируем, пишем отзывы.
Версия 1.10.2-pl
Представлю вам новую версию pdoTools, с исправлениями и улучшениями.Самое интересное, пожалуй, это встроенные мета-теги у сниппета pdoPage, которые предложил Иван Климчук.
Делать ничего не нужно, просто обновитесь и на всех страницах с пагинацией появится что-то вроде
Усли у вас на странице несколько вызовов pdoPage, то нужно выбрать только один, который будет выставлять теги, а у остальных указать новый параметр &setMeta=`0`.
Второе важное изменение: теперь все сниппеты поставляются с пустым параметром &scheme, а это значит, что ссылки у них генерируются исходя из системной настройки link_tag_scheme. Конечно, вы можете указать и своё значение, как и раньше.
Сниппету pdoNeighbors добавлена возможность указания параметра &parents. То есть, теперь выводить ссылки на следующие-предыдущие страницы можно не взирая на реальное положение дел. При этом настоящие соседи документа всегда включаются в выборку.
Не знаю насколько это будет полезно, но предложение такое было.
Сниппет pdoMenu научился правильно показывать &selfClass и &hereClass для документов ссылок. Спасибо вот этому PR.
Ну и, наконец, если указан пустой параметр &titleOfLinks, то для плейсхолдера [[+title]] ссылок меню будет использовано поле pagetitle.
Версия 1.11.0-pl
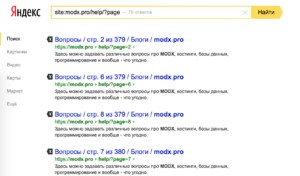
По просьбам общественности был добавлен сниппет pdoTitle, который приятно формирует тег title страницы, включая в неё родителей, пагинацию и поисковые запросы, что приводит к такой индексации сайта поисковиками: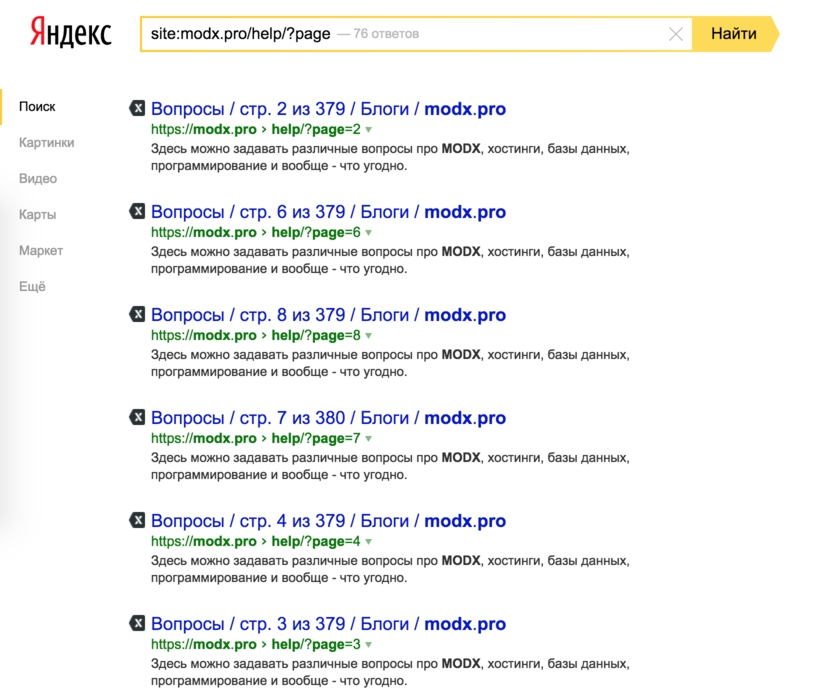
Первая версия сниппета находится здесь, а в pdoTools уже улучшенный вариант, с поддержкой лексиконов, чанков и &ajaxMode сниппета pdoPage.
Оценить работу можно во всех title этого сайта. А почитать документацию вот здесь.
Еще у сниппета pdoPage исправлено перезаписывание скриптов и стилей вызываемых сниппетов. Например, теперь нормально будут грузиться файлы ms2Gallery при вызове его в pdoPage.
Также при включенном &ajaxMode pdoPage вызывается событие pdopage_load, которое можно использовать для обработки навигации:
$(document).on('pdopage_load', function(e, config, response) {
console.log(e, config, response);
});Обновляемся, тестируем, пишем отзывы.
Комментарии: 67
Авторизуйтесь или зарегистрируйтесь, чтобы оставлять комментарии.
Думаю, это нужно исправить, потому что на странице могут быть только циферки.
Поправил, можно обновляться.
А так он же инструмент, который решает свою маленькую задачу, так что концепция не пострадает. Плюс для его полноценной работы нужен pdoCrumbs, т.е. по любому нужно ставить pdoTools.
Даже коммит могу попробовать сделать, если эта бородатая идея приживется.
Постараюсь сделать на неделе.
АндрейP.S. видео гугла
Или там тоже пагинация участвует? Кто может — проясните, а то я в этом вашем SEO не того.
АндрейЕсть страница, но разбитая на 3.
example.com/page.html?p=1
в коде:
example.com/page.html?p=2
в коде:
example.com/page.html?p=3
в коде:
Но ситуация меняется, когда в параметры ссылки добавляется ещё что-то. Вот взгляни пример на этом сайте. В параметр ссылки передаётся (это только например) limit=20, но может быть и limit=40 и т.д. Вообще может передаваться всё, что угодно, в том числе и параметры всевозможных фильтров (в том числе от mSearch2). В коде HTML, само собой, rel=«next» и rel=«prev» указываются, включая эти параметры limit. Но это получается дублирование контента. Чтобы этого избежать, нужно добавить rel=canonical
Код для моего примера будет такой:
На мой взгляд, всё это связано с pdoPage. К тому же, если уж добавлены rel=next и rel=prev, то логичнее было бы добавить и canonical))
АндрейЕсли не требуется канонический адрес, то &setMetaCanonical=`0`
На Яндексе говорят, что canonical нужно использовать, если одна страница доступна по двум адресам.
Что-то мне кажется, что автоматически выставлять canonical — плохая идея. Только автор сайта знает, какие у него там могут быть параметры и зачем. И какое именно сочетание этих параметров делает страницу уникальной.
Так что, от canonical пока предлагаю воздержаться. Кто знает, зачем ему это нужно — сделает сам.
АндрейИ у Гугла на этот счёт более подробно расписано, чем у Яши.
Мета-теги для страниц еще куда ни шло, в конце концов, он эти страницы и делает. Но каноничные url настраивайте себе самостоятельно.
АндрейАндрейПо вашему же примеру, как быть с ссылками? /page.html?p=1&brand=LG и /page.html?p=1&brand=Sony
И таких примеров выше. Василий прав, с prex/next все однозначно, вперед и назад. Вариантов с cannonical в разы выше, а перебрать все комбинации, да еще чтобы и правильно, не реально.
Если готовы предложить рабочий реальный алгоритм 100% определения таких ссылок, ради бога, шлите пулреквест :) Вам только спасибо скажут.
Андрей* на страницу «Показать всё»
* на первую страницу категории
* на эту же страницу за вычетом всех параметров из URL, кроме номера страницы.
Вот и весь алгоритм самый ходовый в 99% случаях. Прикрутить эти вызовы через параметры вызова pdoPage для Василия 10-15 минут, зато пользы уйма!
Никак, это фильтры по производителю и априори дубли /page.html
Фильтры и поиск — это те страницы, которые ПС не рекомендуют к индексации ими же.
К тому же, если быть до конца откровенными, то rel=prev и rel=next Яндекс вообще не учитывает. А rel=canonical учитывает и Гугл и Яндекс.
Не исключено, что данная возможность в будущем появится, но пока не до конца понятно, как правильно должен работать cannonical. Даже в комментах (ваших и нет) к этоq заметке нет однозначного ответа.
АндрейВедь алгоритм корзины miniShop2 тоже не написан с целью охватить все случаи её использования.
И здесь точно так же. &setMeta=`0` отключает использование для prev/next, а, скажем, &setMetaCanonical=`0` — отключает rel=canonical и установлен по дефолту.
В случае такого подхода не нужно будет также лепить лишний сниппет в шапке, определяющий текущую страницу или страницу «Показать всё». Экономия на запросах тоже есть.
Сделай как надо и пришли PR в репозиторий. Ты же для этого сегодня зарегистрировался здесь — чтобы исправить проблему?
АндрейА вот последний вариант по твоей ссылке не катит для пагинации, т.к. все страницы выкинуться, кроме первой из выдачи.
А вообще все так странно с этим каноникалом. Ведь, каталог статей это сборник дублей кусков статей. Не редко встречаются закрытые от индексации пути со знаком вопроса, потому что по сути это дубли, которые нужны людям, а не роботам (у роботов сайтмап). И по логике из выдачи пользователь должен попадать на товар, а не на 15-ую страницу категории товаров(статей), где возможно был во время индексации этот товар(статей).
Сам очень часто напарываюсь при поиске, перехожу на страницу, а там нет того контента, который нашел там яндекс, ибо добавились еще статьи(товары) и нужная статья(товар) уехала в неизвестном направлении. Да с точки зрения владельца сайта к нему пришел посетитель, другое дело что дальше рулетка, я либо воспользуюсь поиском по сайту, чтоб уже найти то, что мне нужно, либо сразу закрою страницу, расстроюсь и скажу что все казлы.
Вообще я всегда думал, что каноникал должен вести именно на основную страницу без ?, потому что все остальные страницы являются его дублем.
Рассмотрим категорию товаров.
У нее есть: Заголовок, Текст описывающий категорию, 100 товаров.
На странице мы выводим 10 товаров.
При твоем подходе в выдачу мы отправляем 10 страниц с одним заголовком и одним текстом, не думаю что это то, чего добивался гугл.
На мой взгляд, самый лучший вариант это закрывать от индексации всю часть после знака вопроса.
АндрейТоже неверно, т.к. пустые (мусорные) страницы будут в выдаче с пометкой в сниппете «индексация документа запрещена в файле robots.txt». А если ввести rel=canonical, то всё логично — в выдаче будет только основная страница, а остальные «сольются» с ней.
вот поэтому и нужны все те инструменты, о которых мы здесь ведём речь — чтобы не было разочарования от перехода на сайт))
АндрейПосмотри видео от гугла и поймёшь, что я имел ввиду.
Гугл видит это так.
Но странно все это. Цитата с Яндекса
Все равно получается мы имеет 10 страниц с одним заголовком и одним текстом, но другим набором товаров.
И получается если мы добавляем 101 товар в начало, то бывший 10-ый товар у нас уже на второй странице, но пока индекс не обновится мы будем приходить к нему на первую и теряться.
АндрейА если использовать только один canonical (без prev/next), то его можно ставить двумя способами:
* для страницы со всеми товарами на одной (без разбивки, т.е. limit=кол-во товаров), но это хорошо, если товаров до 30-50 в категории. Если больше, то не вариант.
* для основной страницы категории (т.е. как раз как ты говорил — без ?...) — это допустимо, но с точки зрения того же гугла неверно. Лучше использовать сразу три тега: prev/next/canonical
АндрейНо в этом случае canonical всё же может помочь, если у нас есть страница «Показать всё» (т.е. с limit=кол-во товаров). Тогда все товары будут на ней и в выдаче как раз будет она. Но если товаров немного, конечно. В остальных случаях от ожидания переиндексации ПС никто не застрахован и никакие пляски с бубном в этом не помогут))
типа:
А то стоит добавить к любой странице ?page=2 и видим в титле что попало. Понятно, что это ерунда, но как-то некрасиво)
Настраивай.
pdoCrumbs вызывается для вывода родителей документа внутри pdoTitle.
Нельзя сделать ®isterJs по умолчанию 0? Чтобы его включали кому это нужно, сейчас на всех сайтах вывелся скрипт. И site_name сделать параметром с дефолтным значением системной настройки, включив его в вывод, чтобы осталось только
Все отлично работает.
Спасибо!
Не помешал бы параметр, который описал товарищ выше, про главную страницу, если документ обозвать как «главная страница», то он так и выведет, а хотелось бы выводить название сайта.
Мне пришлось сделать так:
т.е. сайт мультиязычный, вывожу translate_site_name из контекста.
Прошу прощения, что то у меня тут, видимо
Я только начинаю осваивать ваши расширения, в том числе и PdoTools. Вопросов много, но стараюсь находить ответы через гугл и рытье статей на ваших сайтах.
Возник вопрос, на который, скорей всего, для вас выеденного яйца не стоит, а вот я так пока и не нашел простого готового решения. Решить этот вопрос, как мне видится, можно с помощью сниппета pdoUsers, но я пока не понял, как правильно его для этого вызвать.
Василий, собственно сам вопрос:
Если установленны: Tickets и PdoTools.
Как вывести список всех пользователей группы users по шаблону:
• Имя, логин;
• количество тикетов, которые оставил этот пользователь;
• количество просмотров его тикетов;
• общая сумма балов (лайков), оставленных на его тикеты;
• количество оставленных комментариев на его тикеты;
• количество комментариев, которые оставил этот пользователь;
• общая сумма балов (лайков), оставленных на комментарии текущего пользователя.
Василий, очень надеюсь на ваш подробный ответ. Уверен, что он будет полезен и для большинства других пользователей, ставших на путь освоения MODX и ваших замечательных решений…
ПашокА вообще главный момент в освоении MODX — это тщательное изучение документации. Сам этим иногда принебрегаю выбрав вариант «методом тыка», однако впоследствии всё-же приходится обращаться к докам. Собственно сами доки — docs.modx.pro/
Поледовательность действий такая — читаете внимательно доки, ставите на тестовом сайте компонент, пробуете сделать то что необходимо, снова читаете, снова пробуете… И вот если пройдя эту цепочку у вас останутся вопросы, на которые вы не нашли ответы — стоит задать их тут.
ps. ну это конечно просто мое мнение и я не Василий… Но если вам лень или некогда прочесть то на что человек потратил время и силы, то хз стоит ли тут вообще отвечать.
Вы скажете, так в чем же проблема?! Так вот, Володя, на docs.modx.pro информация достаточно сжато подана, мало примеров. А потому то, что касается вызовов сниппетов с выборками из таблиц баз данных понятно, в основном, только программистам. К сожалению, я еще не программист, впрочем, как и большинство других вебмастеров (как новичков так и мастеров своего дела). Такие как я (а таких большинство) как раз и приходят на подобные сообщества за готовыми решениями, а уже после начинают вникать в самую глубину и суть. Именно благодаря готовым решения появляется желание вникать дальше, развиваться и изучать.
Если же я сейчас начну изучать языки программирования, айтишные дела и т.д., то, получается, только через минимум год я могу вернуться сюда и начать идти по пути сайтостроения на modx. Но правильно ли это, если хочется творить уже сейчас?
А можно подождать недельку новую версию Tickets, где все эти данные будут сразу собираться в одну таблицу.
P.S.
Новую версию жду с нетерпением! И не я один!
Это может ввести кого-то в заблуждение.
Я это к чему… а к тому, что может есть смысл вам создать такого юзереа, чтоб никому подно не было… или просто как-то запретить использовать такое имя…
мелочь, но все же…
Или, как вариант, вообще запретить смену логина…
Необходимо, преимущественно, для реализации своих аякс-страниц, возвращающих новый заголовок.
— но тогда он возвращает пустой результат при любом ответе, кроме тех случаев, когда id=текущему.
у меня почему-то не работает setMeta, а точнее не работает Если вызывает , то ничего не вставляет в head
А вот так уже вставляет , если убрать href.
В чем фокус, никто не сталкивался?
Нужна помощь сообщества и в частности Василия Наумкина, так как перерыл всё и вся — ответа не нашел.
Стоит задача: переопределить вывод Canonical из PdoPage.
Подробнее: есть несколько материалов с одним содержимым, но разными URL, Title и т.п. вещами. Нужно сделать возможным в теле материала (ресурса) при его создании указывать адрес ресурса, который будет основным — Canonical. А если это поле не заполнено, то все продолжает работать, как и раньше — каждый сам себе Каноникал. То есть Канонизировать страницу по требованию, но без ущерба чистоте кода — обновляться в штатном режиме не боясь «затирания» костылей.
Возможна материальная компенсация затрат времени на разработку решения, если таковые будут иметь место.