[DoubleCheck] - Поиск и исправление дублей
И снова всем привет! Эта заметка будет еще короче предыдущей :). В общем все мы знаем и по своему боремся с проблемой после парсинга и/или импорта из говноисточников дублей товаров, компонент ищет дубли по названию товаров (pagetitle) и удаляет эти дубли. Но не просто удаляет, первому вхождению он дает все виртуальные категории удаленных товаров (проще говоря отмечает категории на вкладке товара «Категории»).
P.s. вот так и получается, для сложных компонентов описание в три строки, а для всяких элементарных выходят целые статьи :)
Исходники
Modstore
Использование
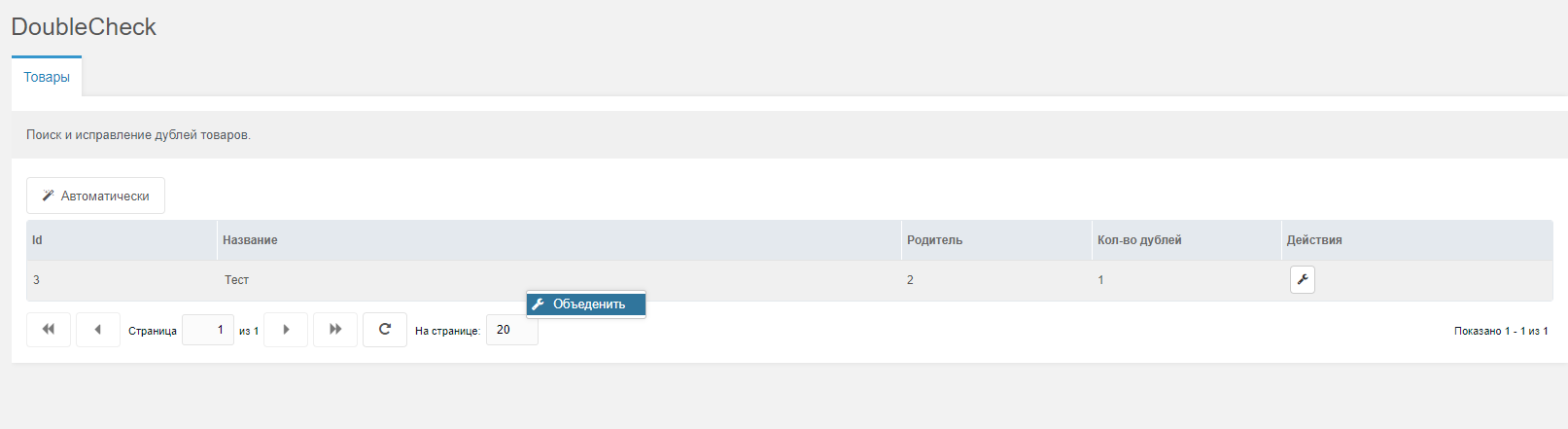
- Пакеты -> miniShop2 -> DoubleCheck
- Проверяем дубли, а после запускаем автоматическое или ручное исправление
P.s. вот так и получается, для сложных компонентов описание в три строки, а для всяких элементарных выходят целые статьи :)
Исходники
Modstore
Комментарии: 22
Авторизуйтесь или зарегистрируйтесь, чтобы оставлять комментарии.
mSync частенько лупит дубли, видимо создает объекты не через процессоры (я не проверял).
Полезная штука
1. По-моему дублями с точки зрения поисковых систем считаются не страницы с одинаковым pagetitle, этот процесс сложнее чем просто одинаковое название. Да и плюс, как я сталкиваюсь в практике, разные разработчики по разному используют поле pagetitle, кто-то отправляет его в h1 на страницу, а кто-то в title
2. Разве модекс позволяет сохранить два ресурса с идентичными названиями? Как могут возникнуть два идентичных pagetitle? Или имеется ввиду похожие названия? Но тогда вопросов еще больше, что есть такое «похожие» и как определять степень схожести. Если на сайте два ресурса «Товар 1» и «Товар 1-1» какой-то из них автоматом будет удален?
1) Скорее всего автор имеет ввиду не дубли «с точки зрения поисковых систем» а дубли с точки зрения modx и тут все гораздо проще.
2) Позволяет, если у них разный алиас, просто создайте два ресурса с pagetitle = modx.pro, но при этом с разными алиасами и все у вас будет отлично.Так-же под похожими подразумевается ===, в вашем примере «Товар 1» !== «Товар 1-1», никакой из них не будет удален.
Хотя возможно я не прав и просто не понял концепцию этого дополнения.
Ну да ладно, это не важно. Я просто тоже не совсем понимаю концепцию этого дополнения.
Вот вам два живых кейса для которых это дополнение писалось и отлично себя показало
1) Парсим сайт, при парсинге записывать в базу через процессоры — самоубийство, по этому пишем в базу прямыми запросами, соответственно uri и alias генерируем уже по окончанию парсинга когда у нас все товары будут в базе данных. Так вот, суть проблемы в том, что на сайте, который мы парсим одни и те же товары могут быть в разных категориях, соответственно у нас это физически разные товары, с одинаковым названием. Что нужно сделать? Правильно, удалить дубли, а основному товару назначить виртуальные категории удаленных товаров, что и делает дополнение. Я уже молчу о том что у «источников» помимо того что товары также могут быть в виртуальных категориях, у них очень часто встречаются еще и физические дубли
2) Часто бывает что поставщики — раздолбаи и база данных, aka выгрузка, у них заполнена через жопу и с разными артикулами бывает по нескольку десятков штук одинаковых позиций
Вообще дополнение для тех, кто знает зачем оно нужно и сталкивался с вышеописанными проблемами)
Я вообще негативно отношусь к парсингу чужих сайтов, но это лично мои «тараканы».
Но если все же приходится это делать, мы не делаем это напрямую в базу, а в экселевский файл, затем контент менеджеры используя формулы экселя удаляют дубли и все ненужное.
Но дело не в этом, а в том, что если менеджер умеет работать с Ексель на высоком уровне, то проверка 50 000 товаров проходит за 5 минут.
виртуальные категории удаленных дублей? А то может мы тут все фигней страдаем и вообще половину компонентов можно сделать в экселе
Я не говорю что ваш компонент плох или не нужен.
Я честно признаюсь, впервые от вас сегодня узнал, что кто-то парсит сайты сразу в базу, а потом борется с дублями. Думал что все работают также с экселевскими файлами. Век живи — век учись.
Или что, при парсинге сайта на вашем сайте создается и точная копия категорий и подкатегорий как на сайте доноре?
Никак, а это в целом играет какую то роль для посетителя?) Ему что в той покажется товар, что в той
Именно, но как я уже ниже писал, в след. обновлении увидим настройку поля сравнения
Для посетителя — нет. Для СЕО — большая разница где физически будет товар. Ведь от этого как минимум зависит URL и уровень вложенности страницы.
Для начала предположим что это один товар — идентичный.
Как ваша программа определяет, какая категория для него реальная?
А как понимает какая категория для него виртуальна?
А другой вариант. Это два разных совершенно ковра. Просто и тот и тот персидский и назвали их — Ковер персидский. Получается что один ковер будет утерян при парсинге? Ведь программа один из ковром посчитает дублем.
В моей практике обычно так — если нужно парсить сайт, это означает что хотят перепродавать чужие товары без спроса с наценкой. И наверное в этом нет ничего ужасного, но меня почему-то с детства приучили что это не хорошо и не честно, поэтому я и называю это моими «тараканами»)
Ну и во-вторых, если поставщик хочет чтобы его товаром пользовались, он придумает удобный способ подачи этого товара — сделает какой-то файл с товаров в xml или json или разработает api для получения товаров. Если этого нет, то скорее всего сайт не хочет, чтобы его товары кто-то «крал».
Хорошо если кто — то, когда — то делал поставщику каких нибудь условных столов для лабораторных целей YML для яндекс маркета, а зачастую поставщики сами напрямую говорят аля «Вы вторые кто к нам обратился с такой просьбой, первые не придумали ничего лучше, как парсить наш сайт, так может и вы будите просто парсить?»