debugParser 1.1.0 и pdoTools 2.1.8
Работаю сейчас над одним сайтом, в котором всё делаю через шаблонизатор Fenom. Проблем нет, сплошное удобство, но из-за принципа работы шаблонизатора непонятно как отлавливать медленные сниппеты.
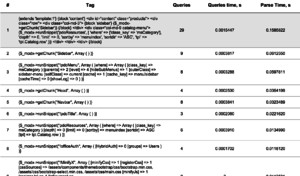
С обычным парсером MODX всё просто — покупаем debugParser и запускаем его на любой странице, добавляя к адресу параметр ?debug=1. Он подменяет собой системный парсер и замеряет время до и после обработки каждого тега на странице, что позволяет выявить тормозов.
А вот как быть с Fenom, который берёт код, компилирует из него php файл и выполняет за один присест, безо всяких тегов и разборов? Оказалось, можно отловить и это.
Для работы нужно:
debugParser научился различать класс запущенного парсера в системе и в зависимости от него, загружает разные версии своего класса.
Таким образом он может отлавливать общие вызовы Fenom при разборе шаблона страницы, а вот чтобы фиксировались вызовы сниппетов и чанков через {$_modx}, пришлось кое-что дописать в сам pdoTools.
Это еще одна причина, по которой нужно использовать безопасную переменную {$_modx}, а не отключенную по умолчанию {$modx}.
Результатом будет то, что вы видите выше на скриншоте. Самое приятное, как обычно, что работает и старый синтаксис:
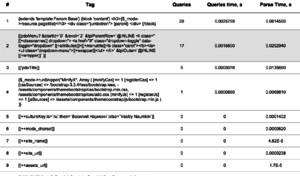
То есть, и старые теги MODX и новые теги Fenom отлавливаются debugParser одинаково.
Помимо уже упомянутой возможности передавать данные о своей работе в debugParser, компонент научился использовать id вместо имени в тегах {include} и {extends}.
Теперь можно писать в шаблонах
Рабочий пример расширения шаблона. Вот базовый шаблон для сайта, который расширяют все остальные:
Вот шаблон страницы поиска, который расширяет шаблон категорий:
При открытии страницы с поиском идёт загрузка этого шаблона, потом категории, а потом уже основного шаблона. Так что, если вы хотите что-то изменить в оформлении — править придётся всего в одном месте. Раньше мне бы пришлось копировать шаблон категории целиком.
Еще в новой версии pdoTools добавлены системные функции {$_modx->getChildIds()} и {$_modx->getParentIds()}, благодаря чему теперь можно писать вот такие проверки:
Продолжаю развивать современную шаблонизацию в MODX Revolution. Напоминаю, что ничего особенного для использования Fenom не требуется — нужно только установить последнюю версию pdoTools.
Если вы хотите использовать его синтаксис не только в чанках сниппетов pdoTools, а вообще везде — нужно включить системную настройку pdotools_fenom_parser.
Обновляемся, тестируем, комментируем изменения. Новые версии компонентов уже доступны в репозитории modstore.pro.
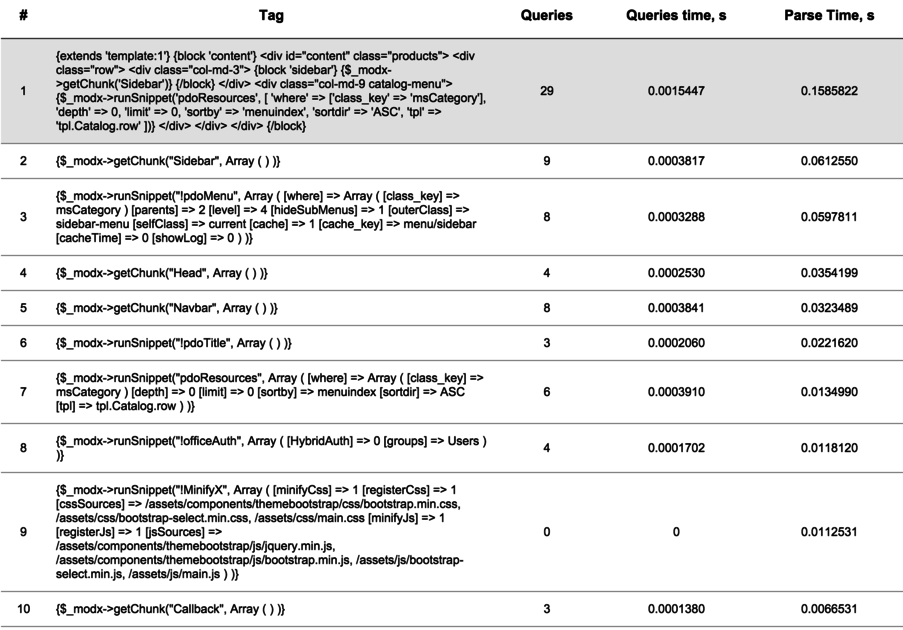
С обычным парсером MODX всё просто — покупаем debugParser и запускаем его на любой странице, добавляя к адресу параметр ?debug=1. Он подменяет собой системный парсер и замеряет время до и после обработки каждого тега на странице, что позволяет выявить тормозов.
А вот как быть с Fenom, который берёт код, компилирует из него php файл и выполняет за один присест, безо всяких тегов и разборов? Оказалось, можно отловить и это.
Для работы нужно:
- pdoTools 2.1.8-pl
- debugParser 1.1.0-pl
- Использование вызовов через {$_modx}, обычный {$modx} отловить не получится
Принцип работы
debugParser научился различать класс запущенного парсера в системе и в зависимости от него, загружает разные версии своего класса.
Таким образом он может отлавливать общие вызовы Fenom при разборе шаблона страницы, а вот чтобы фиксировались вызовы сниппетов и чанков через {$_modx}, пришлось кое-что дописать в сам pdoTools.
Это еще одна причина, по которой нужно использовать безопасную переменную {$_modx}, а не отключенную по умолчанию {$modx}.
Результатом будет то, что вы видите выше на скриншоте. Самое приятное, как обычно, что работает и старый синтаксис:
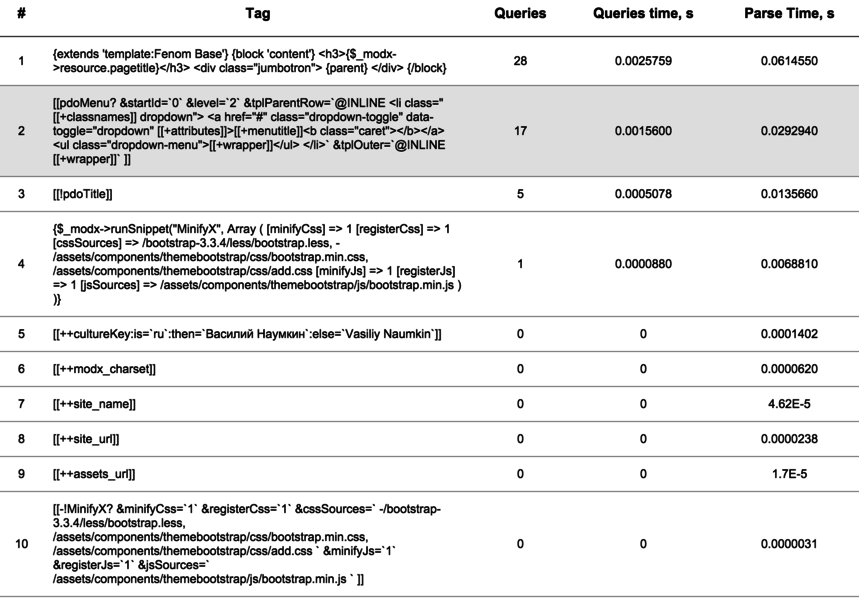
То есть, и старые теги MODX и новые теги Fenom отлавливаются debugParser одинаково.
Изменения в pdoTools
Помимо уже упомянутой возможности передавать данные о своей работе в debugParser, компонент научился использовать id вместо имени в тегах {include} и {extends}.
Теперь можно писать в шаблонах
{extends 'template:10'}{extends 'template:Base Template'}Рабочий пример расширения шаблона. Вот базовый шаблон для сайта, который расширяют все остальные:
<!DOCTYPE html>
<html lang="en">
<head>
{$_modx->getChunk('Head')}
</head>
<body>
{$_modx->getChunk('Navbar')}
<div class="container">
{block 'content'}
<div id="content" class="main">
{$_modx->resource.content}
</div>
{/block}
{$_modx->getChunk('Footer')}
</div>
</body>
</html>{extends 'template:1'}
{block 'content'}
<div id="content" class="products">
<div class="row">
<div class="col-md-3">
{block 'sidebar'}
{$_modx->getChunk('Sidebar')}
{/block}
</div>
<div class="col-md-9">
{block 'crumbs'}
{$_modx->getChunk('Crumbs')}
{/block}
<div id="pdopage">
<div class="rows products">
{block 'filter'}
{$_modx->runSnippet('!mFilter2@Products', [
'showLog' => 0
])}
{/block}
</div>
</div>
</div>
</div>
</div>
{/block}Вот шаблон страницы поиска, который расширяет шаблон категорий:
{extends 'template:3'}
{block 'crumbs'}
{/block}
{block 'filter'}
{$_modx->runSnippet('!mFilter2@Products', [
'parents' => 2,
'forceSearch' => 1,
'showLog' => 1
])}
{/block}При открытии страницы с поиском идёт загрузка этого шаблона, потом категории, а потом уже основного шаблона. Так что, если вы хотите что-то изменить в оформлении — править придётся всего в одном месте. Раньше мне бы пришлось копировать шаблон категории целиком.
Еще в новой версии pdoTools добавлены системные функции {$_modx->getChildIds()} и {$_modx->getParentIds()}, благодаря чему теперь можно писать вот такие проверки:
{if $_modx->resource.id in $_modx->getChildIds(15)}
Этот ресурс является потомком ресурса с id = 15
{else}
Не является
{/if}{if 15 in $_modx->getParentIds($_modx->resource.id)}
Этот ресурс является потомком ресурса с id = 15
{else}
Не является
{/if}Заключение
Продолжаю развивать современную шаблонизацию в MODX Revolution. Напоминаю, что ничего особенного для использования Fenom не требуется — нужно только установить последнюю версию pdoTools.
Если вы хотите использовать его синтаксис не только в чанках сниппетов pdoTools, а вообще везде — нужно включить системную настройку pdotools_fenom_parser.
Обновляемся, тестируем, комментируем изменения. Новые версии компонентов уже доступны в репозитории modstore.pro.
Комментарии: 6
Авторизуйтесь или зарегистрируйтесь, чтобы оставлять комментарии.
Тоже, кстати, уже 2ой сайт делаю исключительно на Fenom! Счастью нет предела, до сих пор вызывает радость то, насколько грамотно можно построить структуру шаблона с использованием шаблонизатора, а не тормозных MODX тегов!
А пока можно почитать про парсер pdoTools и официальную документацию по Fenom.
Будет ли это работать быстрее, чем если допустим, вместо вашего первого шаблона уже во втором «по-стандартному» будет разнесен код в 2 чанка до контента и после? И соответственно будет не три «уровня», а только два, но с дополнительными вызовами двух чанков.
В плане удобства написания кода, расширения, безусловно выигрывают, но вот интересует насколько быстро будет «собираться» конечный шаблон при 3,4 или даже 5м уровне расширения?
А во-вторых, есть системная опция для кэширования скомпилированных шаблонов, она должна помочь пирамидостроителям.
Уж какие сейчас городят конструкции на фильтрах вывода, хуже, по моему, ничего быть не может.