[xParser] 1.3.0 - Регулярные выражения + Кейс

Обработка регулярным выражением полученных данных доступна уже давно, благодаря такой сногсшибательной функциональности Fenom. А с версии 1.3.0 регулярки были внедрены:
а) в конфигурацию задания при указании записи селектора,
б) в поля источника.
Пользователю это даёт более гибкую выборку записей из источника. Под катом пример того, как я извращался при помощи регулярок в xParser.
Кейс
Дано
Возникла потребность распарсить сайт, имеющий странную структуру записей. На CSS или XPath синтаксисе к ним было не подобраться. Пример странной структуры:<div class=content>
<p>
<h2>Какой-то заголовок</h2>
Текст с описанием раздела
<p>
18.01.10 <a href="http://domain.zone/link1.html">Запись 1</a>
< br>Описание записи 1
<p>
24.12.09 <a href="http://domain.zone/link2.html">Запись 2</a>< br>
Описание записи 2
<p>
23.12.09 <a href="http://domain.zone/link3.html">Запись 3</a>
< br>Описание записи 3
<p>
22.12.09 <a href="http://domain.zone/link4.html">Запись 4</a>< br>
Описание записи 4
...
</div>Что мы имеем:
- Запись не содержится в отдельном контейнере. Отсюда сложность получить ее. Решаемо за счет регулярки!
- Теги p в каждой записи открыты, но не закрыты. Решается внутренними средствами xParser без вашего участия!
- Тег br может стоять, как сразу после ссылки, так и на следующей строке под ней. Решаемо за счет регулярки!
Выборка записи
Как обычно, мы создаем задание. Только теперь при указании селектора записи в конфигурации задания, мы можем выбрать синтаксис, среди которых: CSS, XPath, RegExp. Нам нужны регулярные выражения!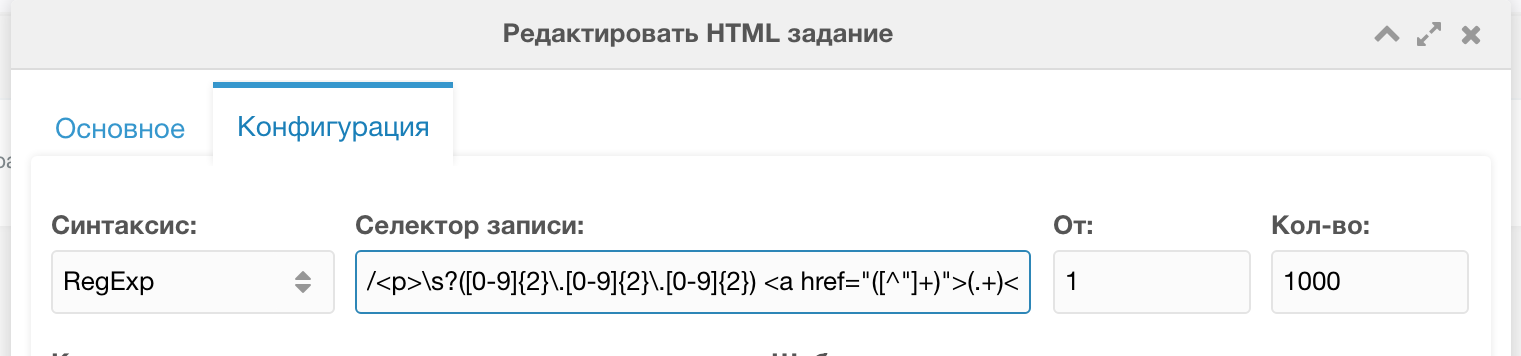
Вот такую регулярку я составил для выборки записей из странной структуры:
/<p>\s?([0-9]{2}\.[0-9]{2}\.[0-9]{2}) <a href="([^"]+)">(.+)<\/a>\s?< br>\s?(.*)\s?<\/p>/uiТаким образом мы получим каждую запись на странице. Всего их было около 100 шт.
Поля источника
После чего нам надо распарсить поля источника. Это я тоже реализовал на регулярных выражениях: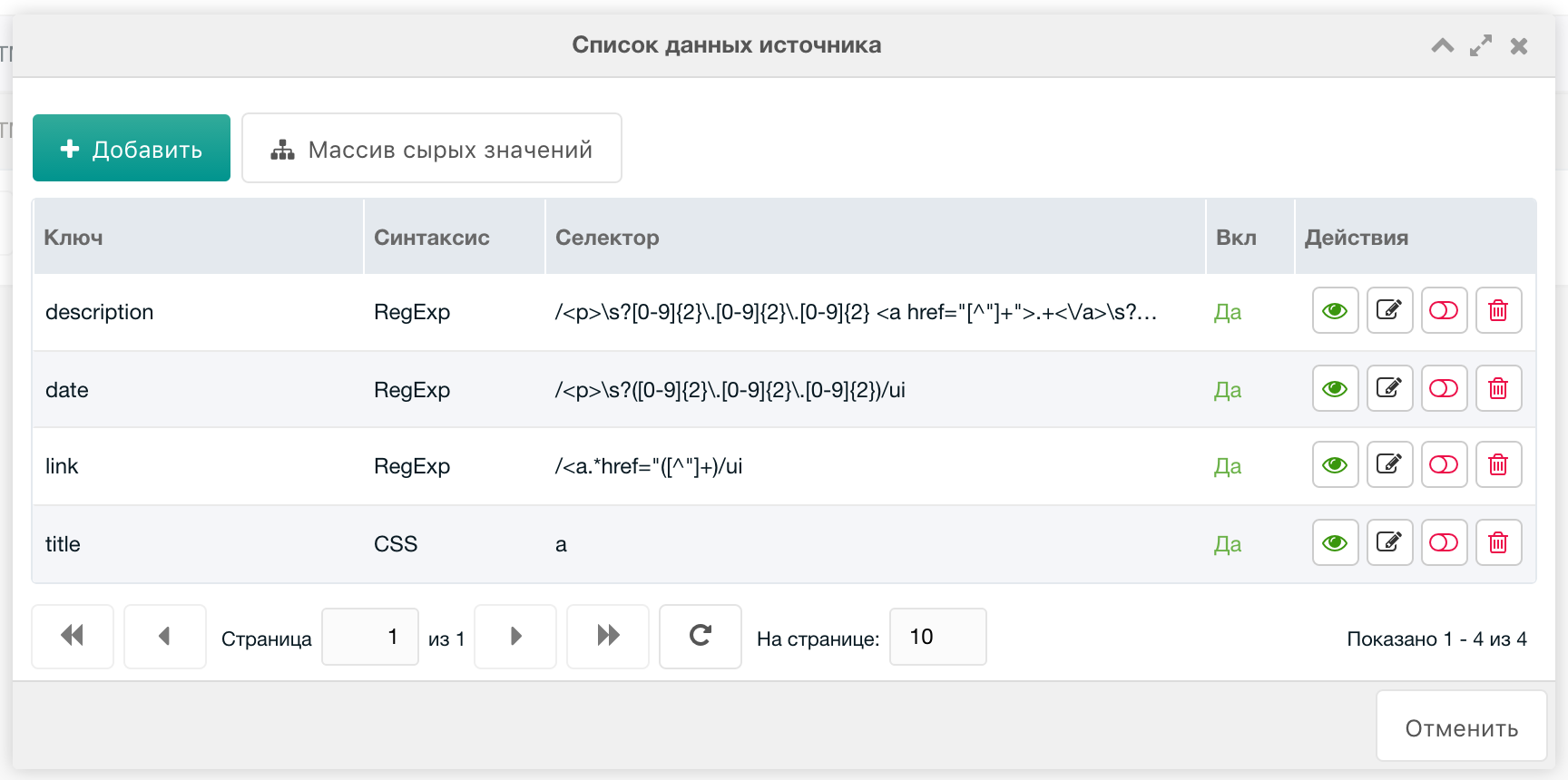
Ссылка:
Синтаксис: RegExp
Ключ: link
Селектор:
/<a.*href="([^"]+)/uiДата:
Синтаксис: RegExp
Ключ: date
Селектор:
/<p>\s?([0-9]{2}\.[0-9]{2}\.[0-9]{2})/uiОписание:
Синтаксис: RegExp
Ключ: description
Селектор:
/<p>\s?[0-9]{2}\.[0-9]{2}\.[0-9]{2} <a href="[^"]+">.+<\/a>\s?< br>\s?(.*)\s?<\/p>/uiИтого
С помощью регулярных выражений можно парсить даже самую сложную структуру. Поэтому всем советую изучать регулярки, хотя бы на том уровне, на котором знаю их я.Дальше думаю сами разберетесь, что с этим всем делать… ;)
А ещё в прошлых версиях были добавлены классные функции:
- Указание кодировки страницы-источника,
- Переменная $_pls в параметры @INLINE чанка в системном поле, которая содержит массив значений, для получения нестандартных полей, например с двоеточием в ключе,
- Можно указывать скачивание медиа для конкретных полей, а не для всего задания в целом,
- Переписан метод xmlToArray на основе DOMDocument, что позволило парсить атрибуты у XML тегов, у которых указан контент. Контент теперь хранится в ключе массива @content, если у тега присутствуют атрибуты.
@INLINE {$guid['@content']}Комментарии: 19
Авторизуйтесь или зарегистрируйтесь, чтобы оставлять комментарии.
У меня, вроде, br не съедаются:
Вот:
Даже спецсимволы типа & lt; br & gt; съедаются…
PS
Обновляться же безбоязненно можно?Не увидел что это версия до которой я и так успешно уже обновился.Спасибо!
Вот тут у вас спрашивали, можно ли результаты парсинга сохрнять в TV.
А можно ли результаты парсинга просто сохранять в бэк-энде, скажем как список в Tickets, но без создания собственно страниц/ресурсов сайта?
link_attributes — нашел в файлике
замечательную функцию:
из которой закомментил
и все заработало!
PS: также в новых версиях хотелось бы видеть функционал вырезки ненужного контента при парсинге.
Результаты парсинга:
Заданий: 1
Создано: 0
Обновлено: 0
Ошибок: 0
Неудачный запусков: 1
Из за чего не удачный запуск то?
Если настроить парсер так, чтобы созданные записи автоматически публиковались, то все работает как и указано в основном задании (записи добавляются, обновляются, до-записываются).
Но если запись автоматически не публикуется (публикуется вручную после проверки и редактирования), то при повторном запуске парсера создается ее дубль. Создается впечатление, что при «ручной» смене статуса записи на опубликованную, парсер уже не проверяет уникальное поле (URL записаный в системном поле introtext).
Пробовал дополнительном задании указать по-умолчанию resource|published = 0, а затем вручную публиковать — проблема остается.
P/S К сожалению, техническая поддержка закончилась 25.03.21.
1. properties tickets при создании (не опубликован)
2. properties tickets после редактирования (не опубликован)
3. properties tickets после редактирования (опубликован)
«Виновник» найден, но как решить данную проблему? Очень бы хотелось «подружить» между собой Tickets и xParser
К сожалению, мои знания не позволяют «доработать Тикетс в том месте, где он затирает неугодные ему properties». НО я нашел способ, как можно обойти данную проблему —
Вот такие «танцы с бубном» для тех, кто не умеет писать код)